Az FSF.hu alapítvány támogatásával sor került a magyar fejlesztésű Lightproof mondatellenőrző keretrendszer magyar és angol moduljainak bővítésére és integrálására, így a LibreOffice következő fejlesztői változata, a 3.5 béta 2 már ezekkel az újdonságokkal jelenhet meg. A modulok külön kiterjesztésként is kipróbálhatók: magyar (28 kB), angol (16 kB).
A magyar mondatellenőrző esetében a földrajzi nevek kezelése az egyik legfontosabb újdonság, például az észak, dél stb. jelölést tartalmazó kötőjeles nevek (Közép-Európa, közép-európai, de semmiképp sem Közép-Európai), budapesti hidak (Erzsébet híd, és nem Erzsébet-híd), egyéb kivételek (Fertő tó, és nem Fertő-tó) kerülnek ellenőrzésre. Az angol Lightproof modul nem szűr ki még annyi nyelvtani hibát, mint a Java-függőség és kisebb fokú integráció miatt elvetett LanguageTool, de nem is ad annyi téves hibajelzést, ami kiemelt fejlesztési szempont volt mind a magyar, mind az angol Lightproof modul esetében. Ezek a szempontok az angol modul néhány szabályával kerültek bemutatásra a planet.libreoffice.org-on. Az angol modul olyan, még nem ismertetett lehetőségei, mint az opcionális oda-vissza mértékegységváltás a gyakoribb amerikai és brit, illetve SI mértékegységek között, vagy a szintén opcionális, a kiadói gyakorlattól függő gondolatjelek (szóközökkel tagolt nagykötőjel, vagy szóköz nélkül használt hosszabb kvirtmínusz) ellenőrzése, később kerülnek részletesen ismertetésre, ahogy a magyar modul egyéb újdonságai is (ebből a legérdekesebb a bővebb webes hibaleírás, ami a LibreOffice 3.5-ben az új Lightproof modulokkal azt eredményezi, hogy egy további kattintással például a magyar helyesírási szabályzat megfelelő pontját is elolvashatjuk a jelzett hibánál).
A modulok beállítására ideiglenesen csak a LibreOffice kiterjesztéskezelőjén (Eszközök » Kiterjesztéskezelő…) keresztül van lehetőség, a feltelepített Lightproof, vagy a 3.5 béta 2 esetében az alapértelmezett magyar, illetve angol szótári kiegészítő nevére, majd a megjelenő Beállítások… gombra történő kattintással.
Szerző: Németh László
Grammar checking in LibreOffice
 Competitive grammar checking would be a nice improvement for LibreOffice. Supported by FSF.hu Foundation, Hungary, I have made two sentence checking patches to the English and Hungarian dictionary extensions of LibreOffice, based on the Lightproof Python UNO environment: see the related issue, the description and the standalone extensions. [Update: source code, Lightproof editor extension]
Competitive grammar checking would be a nice improvement for LibreOffice. Supported by FSF.hu Foundation, Hungary, I have made two sentence checking patches to the English and Hungarian dictionary extensions of LibreOffice, based on the Lightproof Python UNO environment: see the related issue, the description and the standalone extensions. [Update: source code, Lightproof editor extension]
One of the main concepts of “sentence checking” is to break the bad habit of grammar checkers, the annoyingly frequent false alarms. Reporting all potential (but usually not) problems isn’t able to replace proofreading, but very frustrating: “the most useless feature ever added to Microsoft Word […] With this feature, an infinite number of monkeys will analyze your writing and present you with useless grammar complaints while not alerting you to actual grammatical errors because computers don’t understand grammar. Sure, it sounds great on a box—or a promotional Web site—but anyone who knows, knows that grammar checking is a sham. Just say no.” (Jason Snell), “Computer grammar checking really is terrible. […] The things they are good at, like spotting the occasional the the typing error, are very easy there are very few of them. For the most part, accepting the advice of a computer grammar checker on your prose will make it much worse, sometimes hilariously incoherent. If you want an amusing way to whiling away a rainy afternoon, take a piece of literary prose you consider sublimely masterful and run the Microsoft Word™ grammar checker on it, accepting all the suggested changes.” (Geoffrey K. Pullum, cited by Wikipedia), “My take is that we should encourage students to spell check and revise accordingly, but skip the grammar check and proofread instead.” (Mark Pennington). One of the most important improvements of the last few Microsoft Office versions was lowering the “sensitivity” of the grammar checker, responding to customer feedback (source).
In the next few examples I will show how can we make more precise grammar checking:
First rule: we don’t need to catch all mistakes. In fact, we cannot catch all mistakes. We have got only “monkeys”, and often debatable and controversial concepts about grammatical correctness.
Example 1. Capitalization
The following Lightproof rule searches the sentence beginning lower-case letters, and suggests upper-case ones:
^([a-z]) -> =\1.upper() # Missing capitalization?
Unfortunately, there will be many false alarms, especially after abbreviations, because Lightproof has a very simple default sentence boundary detection based on only the paragraph beginning, and sentence ending punctuation (full stop, exclamation mark and question mark). We can check the previous word for abbreviations by a fast Python regex object called abbrev:
^([a-z]) <- not abbrev.search(word(-1)) ->
=\1.upper() # Missing capitalization?
[code]
# pattern matching for common English abbreviations
abbrev = re.compile("(?i)\b([a-z]|acct|approx|\
appt|apr|apt|assoc|asst|aug|ave|avg|co(nt|rp)?|\
ct|dec|defn|dept|dr|eg|equip|esp|est|etc|excl|\
ext|feb|fri|ft|govt?|hrs?|ib(id)?|ie|in(c|t)?|\
jan|jr|jul|lit|ln|mar|max|mi(n|sc)?|mon|Mrs?|\
mun|natl?|neg?|no(rm|s|v)?|nw|obj|oct|org|orig|\
pl|pos|prev|proj|psi|qty|rd|rec|rel|reqd?|resp|\
rev|sat|sci|se(p|pt)?|spec(if)?|sq|sr|st|subj|\
sun|sw|temp|thurs|tot|tues|univ|var|vs)\.")
The sentence segmentation is better, but not enough for a non-intrusive grammar checker (see also the similar decision of Raphael Mudge, author of the more sophisticated and resource-intensive AtD grammar checker here). We will limit the default checking only for paragraph capitalization, more precisely, checking for the first sentence of a paragraph. The difference is important: lower-case list items seem paragraphs for grammar checker clients of LibreOffice, so we check only the paragraphs with more sentences:
^([a-z]) <- re.search("^[a-z].*[.?!] [A-Z]", TEXT)
and not abbrev.search(TEXT) -> = \1.upper()
# Missing capitalization?
(The string variable TEXT contains the full text of the paragraph.)
Second rule: we have to limit false alarms to zero or near zero.
Example 2. Article a/an
The choice of “a” or “an” is determined by phonetic rules and in some cases, also spelling conventions, see Wikipedia. We have to care about the non-standard pronunciation and writing, too, like the form “an HTML” where the letter H pronounced as [ˈheɪtʃ] (see Wikipedia and BBC), and the rare, but similarly allowed spelling conventions: “an hotel”, “an historic” etc. A relevant Lightproof rule to test the “a”:
# pattern "vow" matches words beginning with vowels:
vow [aeiouAEIOU]\w*
a {vow} <- {vow} <> {vow}.upper() and not
({vow} in aA or {vow}.lower() in aA)
and spell({vow}) -> an {vow} # Bad article?
[code]
aA = set(["eucalypti", "eucalyptus", "Eucharist", "Eucharistic",
"euchre", "euchred", "euchring", "Euclid", "euclidean", "Eudora",
"eugene", "Eugenia", "eugenic", "eugenically", "eugenicist",
...])
One of the most interesting elements of the condition is the final spelling dictionary lookup
by the function spell(): this step limits the grammar checking for the known words. Missing words from the exception list (here: “aA”) and from the spelling dictionary won’t result false alarms, for example for the expression “a uremic” or the rare “a usuress”.
Third rule: Don’t hurt people unnecessarily.
Example 3. Spacing
Instead of annoying multiple spaces, like
" +" -> " " # Remove repeating spaces or use tabulators/styles for formatting.
it’s better to check only double (maybe triple) spaces between words. There is living typewriter tradition in the digital age among the users of word processors, too, see sentence spacing with double spaces. So the proposed grammar checker has got three options for spacing: a default option for word spacing, and two optional for sentence spacing and the bad positioning with multiple spaces.
Example 4. Grammar checking based on detailed language data
Recent English module contains only the following example for morphological analysis:
([Tt])his {abc} <- option("grammar") and morph({abc}, "Ns") ->
\1hese {abc}\n\1his, {abc} # Did you mean:
There are several things here to limit false alarms. This is an optional rule (see the option(“grammar”) condition). The morph() function searches unambiguously plural nouns (“Ns”) using Hunspell and language data of Hunspell dictionaries, and the rule checks only lower-case words after “This” or “this”, so the likely bad expression “this mice” will be detected, but not in the “Why is this Mice of Men a challenged book?”. Extending the English dictionary of LibreOffice with part-of-speech and morphological data will help to add more sophisticated grammar checking rules, for example with conversion of the huge rule set of LanguageTool development.
Other concept of sentence checking for LibreOffice is to provide optional tools for proofreading, pre-press formatting and desktop publishing. Not so precise grammar checking is one of these tools, eg. the option “capitalization” of the suggested grammar checker of LibreOffice extends the checking of the capitalization for all sentences, not only for the first ones in the paragraphs.
Feature lists of the recent English module
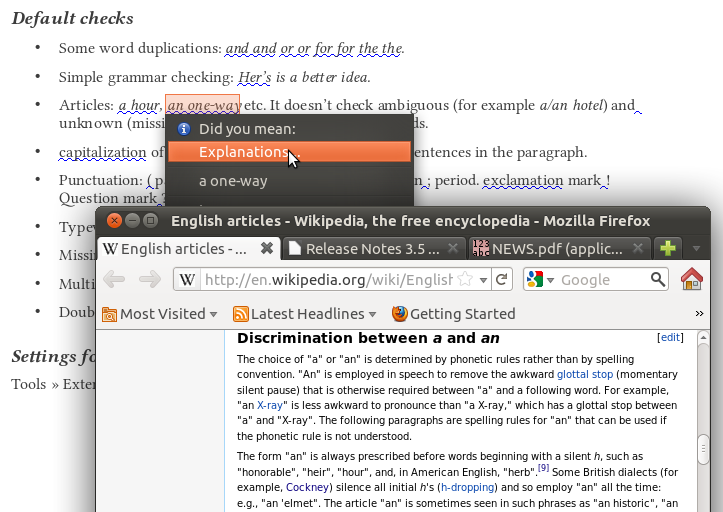
Default checks
- Punctuation (unnecessary spaces before punctuation, missing spaces after punctuation, hyphen instead of n-dash, real double quotation marks and multiplication sign)
- A/an article (with the described improvements)
- Word spacing (not sentence spacing)
- Paragraph capitalization (unwitting paragraph breaks)
- Simple word duplication (and and, or or, for for, the the)
- Longer explanations, using relevant Wikipedia articles (see first screenshot)
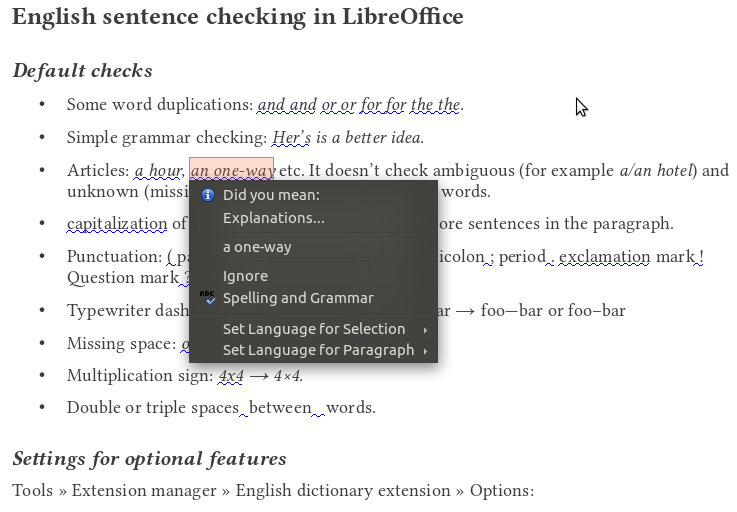
Optional features
- More grammar checks (a few examples using Hunspell morphological analyzer and the English dictionary)
- More punctuation checks (n-dash/m-dash, unpaired quotation marks and parentheses, typographical apostrophe and ellipsis)…
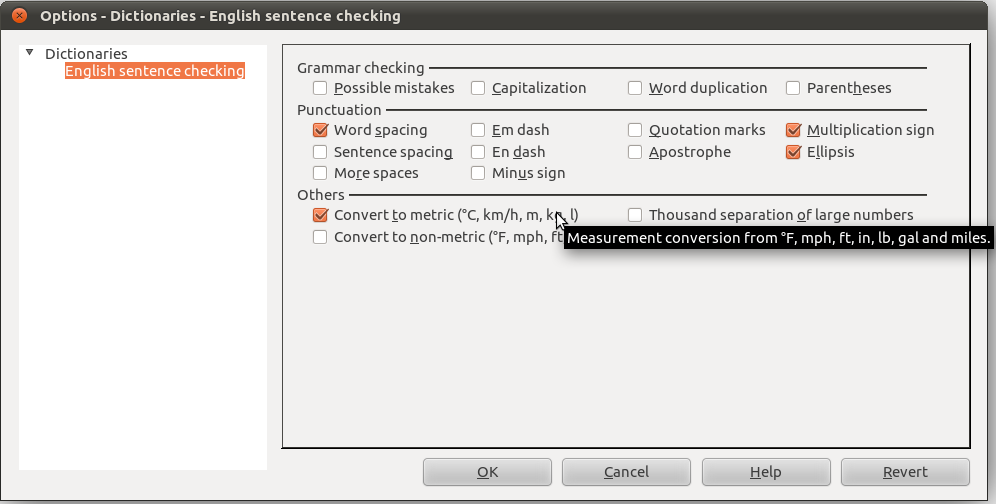
- Measurement conversion (lb/kg, mph/km/h, °F/°C, ft/yd/in/m/cm/mm, mile/km, gal/pint/l)
- Thousand separation (common or ISO)
- Sentence capitalization
- Other word duplication
- Sentence spacing (double spaces)
- Formatting with spaces (more than 3 spaces)
- Settings (a little hidden yet): in Tools » Extension manager… choose “English spelling etc. dictionaries” extension and click on its Options button.
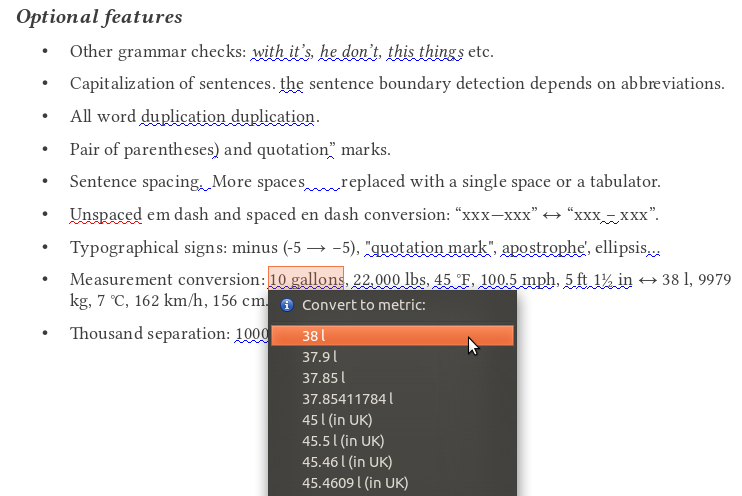
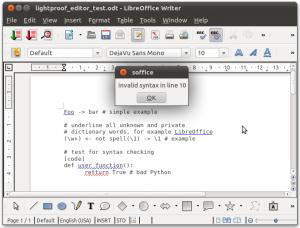
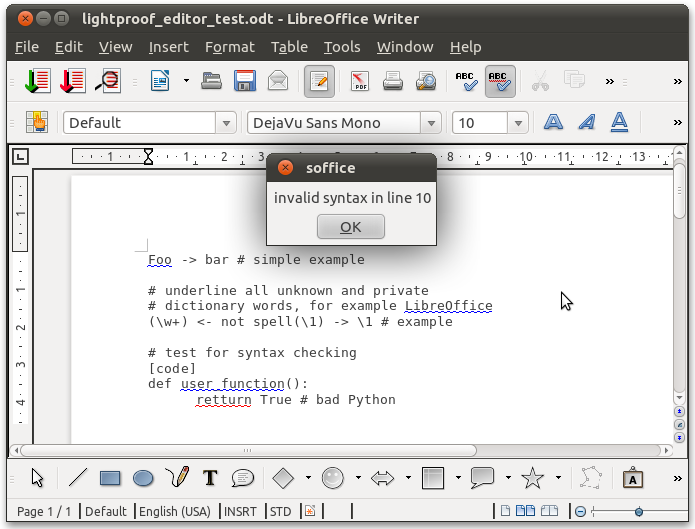
Features of Lightproof rule editor
- LibreOffice extension, downloading, description
- Special grammar checking component + LibreOffice toolbar for rule compiling and debugging
- Run-time compilation and update of its grammar checking component
- Debugging of user code (rule conditions and Python user functions)
Helyesírási javaslat: nem szentírás!
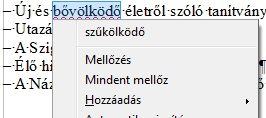 Ahogy a mellékelt képen látható, a LibreOffice helyesírás-ellenőrzője, a Hunspell a „bővölködő életet” „szűkölködő életre” javítaná, ha hagynánk. A humoros példát Gusztin Rudolf küldte. Érdekességképpen, a Hunspell korábbi változata még a bővelkedő és a gyűlölködő szavakat is javasolta, amíg holland támogatással sor nem került a furcsa (zavaróan eltérő és sok) helyesírási javaslat korlátozására. Megoldást a bővölködő szó szótári felvétele fog jelenteni, aminek nincs akadálya, mivel bár régies, nem standard alakváltozatról van szó, nagyon hasonló (egy betűben eltérő) szó híján nem rontja a szószintű helyesírás-ellenőrzés minőségét.
Ahogy a mellékelt képen látható, a LibreOffice helyesírás-ellenőrzője, a Hunspell a „bővölködő életet” „szűkölködő életre” javítaná, ha hagynánk. A humoros példát Gusztin Rudolf küldte. Érdekességképpen, a Hunspell korábbi változata még a bővelkedő és a gyűlölködő szavakat is javasolta, amíg holland támogatással sor nem került a furcsa (zavaróan eltérő és sok) helyesírási javaslat korlátozására. Megoldást a bővölködő szó szótári felvétele fog jelenteni, aminek nincs akadálya, mivel bár régies, nem standard alakváltozatról van szó, nagyon hasonló (egy betűben eltérő) szó híján nem rontja a szószintű helyesírás-ellenőrzés minőségét.
A javaslattevés az egyik legösszetettebb művelet a helyesírás-ellenőrzés során. A Hunspell például előnybe részesíti a javaslattevésnél a tipikus tévesztéseket (j-ly, i-í, ggy-gyj, sőt ős-öss, pl. *erössen-erősen stb.), durva szavakat pedig még összetételekben sem javasol. A legújabb LibreOffice-ban kerültek javításra olyan hibák is, hogy az összetételként elfogadható, de a Hunspell által mégis elutasított gyakori tévesztéseket (pl. szervíz, mint szer+víz a helyes szerviz helyett) többszörös összetételek elején sem fogadja el és nem is javasolja: így most már a szervízkocsi is elutasításra kerül, nemcsak a szervíz és a kocsiszervíz.
Végül egy kapcsolódó idézet a Bibliából: „Mert a kinek van, annak adatik, és bővölködik; de a kinek nincs, az is elvétetik tőle, a mije van.” (Máté 25:29, példabeszéd a talentumokról). A bibliai példázat adta a nevét a szociológia és az olvasáspedagógia Máté-hatásként leírt, gyakran visszás jelenségeinek, miszerint a jómódúak és az iskola első két évében jól olvasók még sikeresebbek lesznek, a szegények és az olvasásban lemaradók még rosszabb helyzetbe kerülnek. A példázat eredeti jelentése azért biztatóbb: mindenkinek megadatik a tehetség valamilyen formában és mértékben, amivel nemcsak élni lehet, hanem kötelességünk is élni, l. a magyar gyerekek számára készült hittan óravázlatot. A szabad szoftverekben nyitottságuknál fogva sokkal inkább összeadódhat a fejlesztők, tesztelők, fordítók és hibabejelentők tehetsége és munkája, ami olyan egyre sikeresebb programokat eredményez, mint a Linux operációs rendszer vagy a LibreOffice.
Magyar fejlesztésű LibreOffice nyelvi eszközök a Firefoxban és az InDesignban
A Mozilla Firefoxban kísérleti jelleggel megjelent a CSS3 webes szabványban rögzített elválasztás támogatása. A kezdetben még hibás magyar elválasztást azóta részben javították, a Firefox friss fejlesztői változatával ezen az oldalon le is tesztelhető.
Az elválasztást a LibreOffice részben magyar fejlesztésű elválasztási programkönyvtára, a Hyphen beépítésével valósították meg a Firefox esetében, így az említett címről letölthető fejlesztői Firefox változat a LibreOffice elválasztási szótárait tartalmazza. Kivéve a magyar esetében, ahol ideiglenes javításként Nagy Bence eredeti, a kettőzött többjegyű mássalhangzók elválasztását nem tartalmazó elválasztási szótára került be javításként a Firefoxba, amíg a Firefox a LibreOffice-hoz hasonlóan nem fogja a Hyphen ez irányú képességeit kihasználni. A LibreOffice gond nélkül elválasztja pl. az asszonnyá szót asz•szony•nyá formájában. Viszont a LibreOffice elválasztási szótárával a Firefox fejlesztői változata még a hibás as•szon•nyá alakban választ el. Ezért cserélték le a magyar elválasztási szótárat egyszerűbbre a Mozillánál, hiába volna lehetőség a Hyphennel a jó elválasztásra, illetve hiába igénylik a speciális elválasztást hosszú-hosszú idő (pl. itt a svédek 1996) óta.
A piacvezető kereskedelmi kiadványszerkesztő, az Adobe InDesign legutóbbi változatának egyik újdonsága a Hunspell helyesírási szótárak támogatása, a Firefoxot, a Mac OS X-et és más programokat követve ezzel. A Hunspell az OpenOffice.org MySpell helyesírás-ellenőrző komponensének magyar továbbfejlesztésével jött létre. A LibreOffice a legfrissebb változatát tartalmazza, amivel mintegy száz, köztük speciális karakterkódolású vagy a magyarhoz hasonlóan bonyolult toldalékolású nyelvhez nyújt helyesírási segítséget.
Az InDesign 5.5 a bejelentés szerint a Hyphen könyvtárat is tartalmazza már, de ahogy egy katalán hibabejelentésből kiderült, ugyanúgy várni kell még arra, hogy a Hyphen által helyesen kezelt speciális elválasztású szavakat (a katalánban a hosszú l·l-ből esik ki a pont az elválasztásnál) ténylegesen el is tudja választani a szövegszedés során.
Új képesség és használata: képfelbontás a Writerben
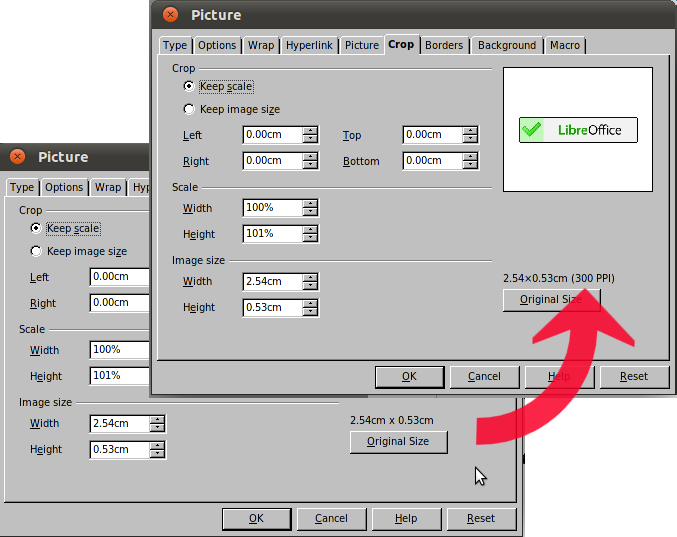 Ahogy egy korábbi esettanulmányban már szerepelt, a képek jó minőségű nyomtatásához megfelelő képfelbontásra van szükség. Ezt támogatandó a LibreOffice Writer következő változata kijelzi a beillesztett képek alapértelmezett felbontását PPI-ben (pixel per hüvelyk) egy magyar fejlesztésű programfoltnak köszönhetően. Bár a programfolt csak pár soros, a LibreOffice kiadványszerkesztőként való használata szempontjából fontos fejlesztésről van szó: Fernand Vanrie – a belga PMG főmunkatársa, amely kiadó a tevékenységét az OpenOffice.org-ra, mint kiadványszerkesztőre alapozza – a jobb képkezelés első lépésének nevezte. “Új képesség és használata: képfelbontás a Writerben” bővebben
Ahogy egy korábbi esettanulmányban már szerepelt, a képek jó minőségű nyomtatásához megfelelő képfelbontásra van szükség. Ezt támogatandó a LibreOffice Writer következő változata kijelzi a beillesztett képek alapértelmezett felbontását PPI-ben (pixel per hüvelyk) egy magyar fejlesztésű programfoltnak köszönhetően. Bár a programfolt csak pár soros, a LibreOffice kiadványszerkesztőként való használata szempontjából fontos fejlesztésről van szó: Fernand Vanrie – a belga PMG főmunkatársa, amely kiadó a tevékenységét az OpenOffice.org-ra, mint kiadványszerkesztőre alapozza – a jobb képkezelés első lépésének nevezte. “Új képesség és használata: képfelbontás a Writerben” bővebben
Graphite 2 tesztelés és eredményei
 A Graphite 2 a SIL International alapoktól újraírt Graphite betűtechnológiai motorja, amely teljesítményben felveszi a versenyt a hasonló OpenType megoldásokkal. Az első tesztek, és némi fordítási hiba után integrálására csak a LibreOffice 3.4-ben került sor. Mivel nemcsak a kiadványszerkesztési képességeket, hanem egyéb alapvető funkciókat is érint a változás, ezért az FSF.hu Alapítvány támogatásával alaposabb tesztelésére került sor az elmúlt hetekben. A talált és bejelentett hibák alapján még úgy tűnik, hogy korai volt az átállás, de mivel a hibák egy része már javításra került, remélhető, hogy a többié sem fog sokat késlekedni. “Graphite 2 tesztelés és eredményei” bővebben
A Graphite 2 a SIL International alapoktól újraírt Graphite betűtechnológiai motorja, amely teljesítményben felveszi a versenyt a hasonló OpenType megoldásokkal. Az első tesztek, és némi fordítási hiba után integrálására csak a LibreOffice 3.4-ben került sor. Mivel nemcsak a kiadványszerkesztési képességeket, hanem egyéb alapvető funkciókat is érint a változás, ezért az FSF.hu Alapítvány támogatásával alaposabb tesztelésére került sor az elmúlt hetekben. A talált és bejelentett hibák alapján még úgy tűnik, hogy korai volt az átállás, de mivel a hibák egy része már javításra került, remélhető, hogy a többié sem fog sokat késlekedni. “Graphite 2 tesztelés és eredményei” bővebben
Towards Desktop Publishing – angolul és magyarul
 Letölthetők a párizsi nemzetközi LibreOffice konferencián elhangzott, a LibreOffice-szal, mint kiadványszerkesztővel foglalkozó előadás angol nyelvű diái (PDF, 4 Mb), amelyek képekkel is illusztrálják a LibreOffice kiemelkedő kiadványszerkesztési képességeit. Az előadáson a tervezett fejlesztések mellett a kifejezetten magyar vonatkozású újdonságok is bemutatásra kerültek (korábban l. Writer jegyzet, példa kiadvány és betűk). Az egyik ilyen újdonság a betűtechnológia (Graphite 2 és a Linux Libertine G) teszteléséhez készülő Biblia, ami kiválóan alkalmas a LibreOffice és az OpenDocument képességeinek bemutatására is. (A múlt héten kiadott – l. bejelentés – (és a mai napon a LibreOffice-ba is frissített) elválasztási programkönyvtár egyik javítása is a Bibliához kötődik: a mondatokat számozó indexek korábban elrontották az elválasztást.) A Károli Biblia szövegét tartalmazó HTML forrásból egy Unix paranccsorral és egy rövidke ODFpy Python programmal készül el az az OpenDocument formátumú állomány, ami a LibreOffice-szal közel 800 oldalas kiadványként kerül kiszedésre, olyan – a LibreOffice-ban rendelkezésre álló – tipográfiai megoldásokkal (például valódi kiskapitálisok, magyar tipográfiának megfelelő térközök az írásjelek előtt, optikai margó az írásjelek kilógatásával, valódi betűfokozatok, magyar vonatkozású ligatúrák), amivel a kereskedelmi kiadványszerkesztők körében sem mindig találkozni, nemhogy a LibreOffice-szal hagyományosan egy kategóriába sorolt Microsoft Office-nál.
Letölthetők a párizsi nemzetközi LibreOffice konferencián elhangzott, a LibreOffice-szal, mint kiadványszerkesztővel foglalkozó előadás angol nyelvű diái (PDF, 4 Mb), amelyek képekkel is illusztrálják a LibreOffice kiemelkedő kiadványszerkesztési képességeit. Az előadáson a tervezett fejlesztések mellett a kifejezetten magyar vonatkozású újdonságok is bemutatásra kerültek (korábban l. Writer jegyzet, példa kiadvány és betűk). Az egyik ilyen újdonság a betűtechnológia (Graphite 2 és a Linux Libertine G) teszteléséhez készülő Biblia, ami kiválóan alkalmas a LibreOffice és az OpenDocument képességeinek bemutatására is. (A múlt héten kiadott – l. bejelentés – (és a mai napon a LibreOffice-ba is frissített) elválasztási programkönyvtár egyik javítása is a Bibliához kötődik: a mondatokat számozó indexek korábban elrontották az elválasztást.) A Károli Biblia szövegét tartalmazó HTML forrásból egy Unix paranccsorral és egy rövidke ODFpy Python programmal készül el az az OpenDocument formátumú állomány, ami a LibreOffice-szal közel 800 oldalas kiadványként kerül kiszedésre, olyan – a LibreOffice-ban rendelkezésre álló – tipográfiai megoldásokkal (például valódi kiskapitálisok, magyar tipográfiának megfelelő térközök az írásjelek előtt, optikai margó az írásjelek kilógatásával, valódi betűfokozatok, magyar vonatkozású ligatúrák), amivel a kereskedelmi kiadványszerkesztők körében sem mindig találkozni, nemhogy a LibreOffice-szal hagyományosan egy kategóriába sorolt Microsoft Office-nál.
Erről és egyéb fejlesztésekről bővebben november 12-én lesz szó Budapesten, az FSF.hu Alapítvány által szervezett Szabad Szoftver Konferencia és Kiállítás egyik előadásaként.
Towards Desktop Publishing
If you were not able to attend this presentation, please find the slides online. There are some really nice examples for the new InDesign-like typographical features of LibreOffice.
Unfortunatelly, I was not able to attend the conference, so many thanks to András Tímár for the presentation.
Megújult magyar elválasztási minták és programkönyvtár
Nagy Bence, a méltán népszerű moly.hu könyves oldal gazdája a nyáron MPL/GPL/LGPL licenc alatt adta ki a szintén általa gondozott Huhyphn TeX magyar elválasztási mintákat (eddig csak egyedi LGPL engedély birtokában kerültek be az LGPL-es LibreOffice alá a magyar elválasztási minták). A LibreOffice-ba a minták bővített változata kerül be, mivel a TeX szedőrendszerrel szemben a LibreOffice automatikusan is képes elválasztani a kettőzött többjegyű mássalhangzókat (a Hyphen programkönyvtár Liang–Knuth-féle elválasztási algoritmusának magyar fejlesztésű kiterjesztésével.) A fejlesztéshez kapcsolódóan a LibreOffice elválasztási programkönyvtára is (sok) új változattal jelentkezik, ami a magyar elválasztás számára is tartogat érdekességeket. Ilyen például a kötőjeles szavak OpenOffice.org 3.3-mal elromlott elválasztásának javítása: pl. az ideig-ó•ráig, magyar–o•rosz szavakban jelölt hibás elválasztási helyek már nem fognak jelentkezni a LibreOffice javított változatában. Sőt, a kötőjeltől két betű távolságra lévő, ebben az esetben azonban még zavaróan közeli, pl. Kossuth-dí•jas, hé•be-hó•ba, helyesírás-el•lenőrző elválasztások is letilthatók lettek (ez az elválasztási mintaállomány elején található COMPOUNDLEFTHYPHENMIN=3 és COMPOUNDRIGHTHYPHENMIN=3 értékek 2-re állításával kapcsolható vissza).
“Megújult magyar elválasztási minták és programkönyvtár” bővebben
Lively Alphabet – kifestőkönyv és DTP példa
 A LibreOffice évfordulójára megjelent nyílt forrású Lively Alphabet (PDF, 4,7 Mb) állatos kifestő a Writer jegyzethez hasonlóan jó példája a LibreOffice kiadványszerkesztési lehetőségeinek. Bemutatja a LibreOffice SVG vektorgrafikus képformátum-kezelését és megújult betűkészleteit, elsősorban a kifejezetten nagy betűmérethez tervezett, különösen szép Linux Libertine Display betűváltozatot. A GNU GFDL szabad dokumentációs licenc alatt kiadott nagyméretű (47 Mb) ODF forrásdokumentum betöltéséhez és módosításához kapcsoljuk ki az élsimítást az Eszközök » Beállítások » LibreOffice » Nézet lapon. A könyv hozzávalói az egyszerű szöveg és a LibreOffice új betűi mellett a Wikimedia Commonsból, nagyrészt a Pearson Scott Foresman tankönyvkiadó adományából származó és a Wikipédia által digitalizált képek, amelyek az Inkscape rajzprogrammal (vagyis az Inkscape-be integrált Potrace programmal) lettek vektorizálva a jobb felbontás és a szabad méretezhetőség végett.
A LibreOffice évfordulójára megjelent nyílt forrású Lively Alphabet (PDF, 4,7 Mb) állatos kifestő a Writer jegyzethez hasonlóan jó példája a LibreOffice kiadványszerkesztési lehetőségeinek. Bemutatja a LibreOffice SVG vektorgrafikus képformátum-kezelését és megújult betűkészleteit, elsősorban a kifejezetten nagy betűmérethez tervezett, különösen szép Linux Libertine Display betűváltozatot. A GNU GFDL szabad dokumentációs licenc alatt kiadott nagyméretű (47 Mb) ODF forrásdokumentum betöltéséhez és módosításához kapcsoljuk ki az élsimítást az Eszközök » Beállítások » LibreOffice » Nézet lapon. A könyv hozzávalói az egyszerű szöveg és a LibreOffice új betűi mellett a Wikimedia Commonsból, nagyrészt a Pearson Scott Foresman tankönyvkiadó adományából származó és a Wikipédia által digitalizált képek, amelyek az Inkscape rajzprogrammal (vagyis az Inkscape-be integrált Potrace programmal) lettek vektorizálva a jobb felbontás és a szabad méretezhetőség végett.