 Megjelent a LibreOffice 3.5.3 verziójának hordozható (portable) változata. Ez változat is teljes értékű irodai programcsomag, mely kompatibilis a kiegészítőkkel.
Megjelent a LibreOffice 3.5.3 verziójának hordozható (portable) változata. Ez változat is teljes értékű irodai programcsomag, mely kompatibilis a kiegészítőkkel.
A bejelentés a Portableapps.com oldalon, a program letöltése innét lehetséges.
Megjelent a LibreOffice 3.5.3 verziójának hordozható (portable) változata. Ez változat is teljes értékű irodai programcsomag, mely kompatibilis a kiegészítőkkel.
A bejelentés a Portableapps.com oldalon, a program letöltése innét lehetséges.
 Megjelent a LibreOffice 3.5-ös sorozatból a negyedik kiadás, a 3.5.3. A javított hibák listája szokás szerint két részletben olvasható el, RC1 és RC2. A hivatalos bejelentés kiemeli, hogy áprilisban 34 új fejlesztő csatlakozott a LibreOffice projekthez, ez 2011 januárja óta a legtöbb. Ez a csúcs részben a Google Summer of Code projektnek köszönhető, melynek keretében 10 hallgató fog a nyáron LibreOffice-t fejleszteni. A témák:
Megjelent a LibreOffice 3.5-ös sorozatból a negyedik kiadás, a 3.5.3. A javított hibák listája szokás szerint két részletben olvasható el, RC1 és RC2. A hivatalos bejelentés kiemeli, hogy áprilisban 34 új fejlesztő csatlakozott a LibreOffice projekthez, ez 2011 januárja óta a legtöbb. Ez a csúcs részben a Google Summer of Code projektnek köszönhető, melynek keretében 10 hallgató fog a nyáron LibreOffice-t fejleszteni. A témák:
Mint az ahogy már megszokható, (pl. itt) ezúttal is készült portable (azaz hordozható, USB kulcsra telepíthető) változat a LibreOffice 3.5.2 verziójából.
A portable változat teljes értékű irodai programcsomag, amely tartalmazza a hagyományos telepítés által elérhető funkciókat. A portable változat megegyezik az eredeti kiadással, új funkciót nem ad a programcsomaghoz, ellenben telepíthetőek – kompatibilisek vele – a legkülönfélébb kiegészítők (vagy itt).
Ezúttal is két telepítőkészlet érhető el: egy kisebbik a leggyakoribb nyelvekkel és egy másik, nagyobb az összes támogatott nyelvvel.
Ahogy már korábban megszokhattuk a LibreOffice újabb és újabb kiadásaival majdnem egy időben elérhető azoknak hordozható (USB kulcsra, „tolltartóra” telepíthető, ún. portable) változata.
A hordozható változat egyenértékű a hagyományos változattal, a megszokott – és jól bevált – kiegészítőinket (pl. Lightproof) ugyanúgy feltelepíthetjük és használhatjuk, mint a normál kiadások esetében.
A 3.5-ös változat esetében is kétféle telepítőkészlet érhető el: 1. normál (tartalmazza a magyar nyelvet), 2. all language (minden támogatott nyelv). A portable változatok tartalmazzák a 3.5-ös minden újdonságát (újdonságok listája).
A hivatalos bejelentés itt olvasható, a program pedig innét tölthető le.
Mintegy 8 hónap fejlesztésének eredményeképp megjelent a LibreOffice 3.5, pontosabban a 3.5.0, mert ez is egy sorozat lesz, az első stabil verziót több hibajavító kiadás fogja követni a következő hónapokban. A hivatalos bejelentés és a feature lista már elérhető, ez utóbbit magyarra is le lesz fordítva, ha minden jól megy.
Ebben a cikkben azokat az újdonságokat szeretném kiemelni, amelyek magyar fejlesztők nevéhez köthetők.
“Megjelent a LibreOffice 3.5” bővebben
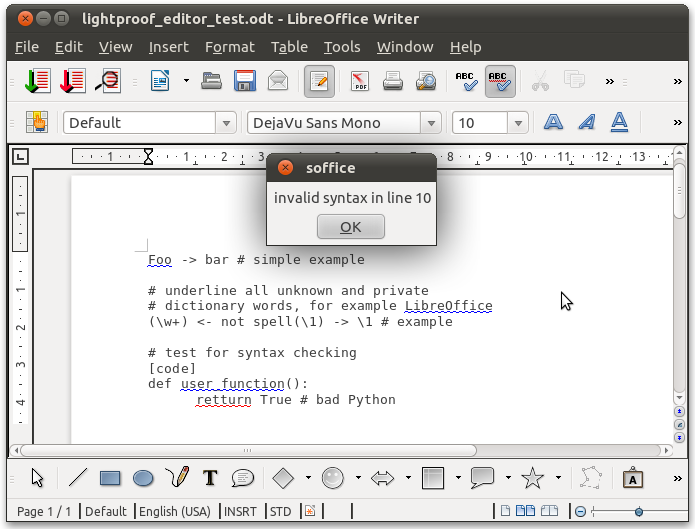 Hivatalosan is helyet kapott a mondatellenőrzők fejlesztésére szolgáló Lightproof keretrendszer a LibreOffice forráskódjában [a git fában szereplő „the awesome python grammar checker” meghatározás Michael Meeks, a LibreOffice vezető fejlesztőjének humorát dicséri]. Az FSF.hu Alapítvány által támogatott fejlesztés fő újdonsága a kódtisztítás és a LibreOffice-ban alapértelmezetté váló magyar mondatellenőrzés mellett a külön is letölthető Lightproof szabályszerkesztő. Ez a LibreOffice-kiegészítő nagymértékben leegyszerűsíti a magyar és más mondatellenőrzők fejlesztését, mivel a LibreOffice Writeren belül képes ellenőrizni, lefordítani és a futó mondatellenőrzőben frissíteni a helyenként összetett, és tetszőleges Python felhasználói programkódot is tartalmazó mondat-ellenőrzési szabályokat (ezek nem feltétlenül függetlenek a LibreOffice-tól, mivel képesek a LibreOffice más komponenseit is használni, így a magyar mondatellenőrző a LibreOffice Hunspell helyesírás-ellenőrző komponensét használja alaktani elemzésre, a brit és amerikai mértékegységek opcionális átalakításánál a Calc táblázatkezelő megfelelő függvényét hívja meg, vagy a számmal és számnévvel is leírt pénzmennyiségek konzisztenciájának ellenőrzésénél a LibreOffice – jelenleg még külön telepíthető – Numbertext kiegészítőjétől függ).
Hivatalosan is helyet kapott a mondatellenőrzők fejlesztésére szolgáló Lightproof keretrendszer a LibreOffice forráskódjában [a git fában szereplő „the awesome python grammar checker” meghatározás Michael Meeks, a LibreOffice vezető fejlesztőjének humorát dicséri]. Az FSF.hu Alapítvány által támogatott fejlesztés fő újdonsága a kódtisztítás és a LibreOffice-ban alapértelmezetté váló magyar mondatellenőrzés mellett a külön is letölthető Lightproof szabályszerkesztő. Ez a LibreOffice-kiegészítő nagymértékben leegyszerűsíti a magyar és más mondatellenőrzők fejlesztését, mivel a LibreOffice Writeren belül képes ellenőrizni, lefordítani és a futó mondatellenőrzőben frissíteni a helyenként összetett, és tetszőleges Python felhasználói programkódot is tartalmazó mondat-ellenőrzési szabályokat (ezek nem feltétlenül függetlenek a LibreOffice-tól, mivel képesek a LibreOffice más komponenseit is használni, így a magyar mondatellenőrző a LibreOffice Hunspell helyesírás-ellenőrző komponensét használja alaktani elemzésre, a brit és amerikai mértékegységek opcionális átalakításánál a Calc táblázatkezelő megfelelő függvényét hívja meg, vagy a számmal és számnévvel is leírt pénzmennyiségek konzisztenciájának ellenőrzésénél a LibreOffice – jelenleg még külön telepíthető – Numbertext kiegészítőjétől függ).
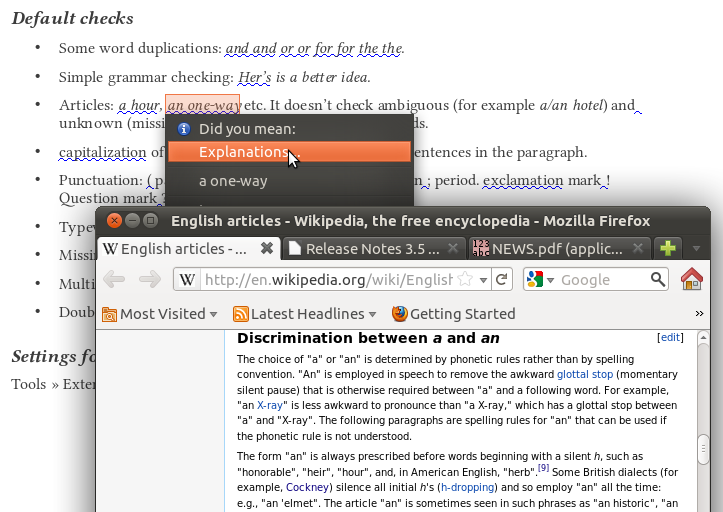
 A hamarosan kiadásra kerülő LibreOffice 3.5 új, alapértelmezett magyar mondatellenőrzője segít a gyakran eltévesztett földrajzi nevek helyesírásában (lásd bővebben). Érdekes és hasznos újdonság, hogy a LibreOffice 3.5 új lehetőségének köszönhetően a nehezen értelmezhető hibajelzéseknél bővebb magyarázatot is kérhetünk, a magyar Wikipédia kapcsolódó szócikkét olvasásra megnyitva. A magyar mondatellenőrző legújabb, 1.4.3-as változata is elérhető már külön kiegészítőként, pár kisebb hibajavítással (például nem húzza alá a mínusz számokat a Writer táblázatcellákban, téves gondolatjeles felsorolásnak gondolva).
A hamarosan kiadásra kerülő LibreOffice 3.5 új, alapértelmezett magyar mondatellenőrzője segít a gyakran eltévesztett földrajzi nevek helyesírásában (lásd bővebben). Érdekes és hasznos újdonság, hogy a LibreOffice 3.5 új lehetőségének köszönhetően a nehezen értelmezhető hibajelzéseknél bővebb magyarázatot is kérhetünk, a magyar Wikipédia kapcsolódó szócikkét olvasásra megnyitva. A magyar mondatellenőrző legújabb, 1.4.3-as változata is elérhető már külön kiegészítőként, pár kisebb hibajavítással (például nem húzza alá a mínusz számokat a Writer táblázatcellákban, téves gondolatjeles felsorolásnak gondolva).
Az FSF.hu alapítvány támogatásával sor került a magyar fejlesztésű Lightproof mondatellenőrző keretrendszer magyar és angol moduljainak bővítésére és integrálására, így a LibreOffice következő fejlesztői változata, a 3.5 béta 2 már ezekkel az újdonságokkal jelenhet meg. A modulok külön kiterjesztésként is kipróbálhatók: magyar (28 kB), angol (16 kB).
A magyar mondatellenőrző esetében a földrajzi nevek kezelése az egyik legfontosabb újdonság, például az észak, dél stb. jelölést tartalmazó kötőjeles nevek (Közép-Európa, közép-európai, de semmiképp sem Közép-Európai), budapesti hidak (Erzsébet híd, és nem Erzsébet-híd), egyéb kivételek (Fertő tó, és nem Fertő-tó) kerülnek ellenőrzésre. Az angol Lightproof modul nem szűr ki még annyi nyelvtani hibát, mint a Java-függőség és kisebb fokú integráció miatt elvetett LanguageTool, de nem is ad annyi téves hibajelzést, ami kiemelt fejlesztési szempont volt mind a magyar, mind az angol Lightproof modul esetében. Ezek a szempontok az angol modul néhány szabályával kerültek bemutatásra a planet.libreoffice.org-on. Az angol modul olyan, még nem ismertetett lehetőségei, mint az opcionális oda-vissza mértékegységváltás a gyakoribb amerikai és brit, illetve SI mértékegységek között, vagy a szintén opcionális, a kiadói gyakorlattól függő gondolatjelek (szóközökkel tagolt nagykötőjel, vagy szóköz nélkül használt hosszabb kvirtmínusz) ellenőrzése, később kerülnek részletesen ismertetésre, ahogy a magyar modul egyéb újdonságai is (ebből a legérdekesebb a bővebb webes hibaleírás, ami a LibreOffice 3.5-ben az új Lightproof modulokkal azt eredményezi, hogy egy további kattintással például a magyar helyesírási szabályzat megfelelő pontját is elolvashatjuk a jelzett hibánál).
A modulok beállítására ideiglenesen csak a LibreOffice kiterjesztéskezelőjén (Eszközök » Kiterjesztéskezelő…) keresztül van lehetőség, a feltelepített Lightproof, vagy a 3.5 béta 2 esetében az alapértelmezett magyar, illetve angol szótári kiegészítő nevére, majd a megjelenő Beállítások… gombra történő kattintással.
 Competitive grammar checking would be a nice improvement for LibreOffice. Supported by FSF.hu Foundation, Hungary, I have made two sentence checking patches to the English and Hungarian dictionary extensions of LibreOffice, based on the Lightproof Python UNO environment: see the related issue, the description and the standalone extensions. [Update: source code, Lightproof editor extension]
Competitive grammar checking would be a nice improvement for LibreOffice. Supported by FSF.hu Foundation, Hungary, I have made two sentence checking patches to the English and Hungarian dictionary extensions of LibreOffice, based on the Lightproof Python UNO environment: see the related issue, the description and the standalone extensions. [Update: source code, Lightproof editor extension]
One of the main concepts of “sentence checking” is to break the bad habit of grammar checkers, the annoyingly frequent false alarms. Reporting all potential (but usually not) problems isn’t able to replace proofreading, but very frustrating: “the most useless feature ever added to Microsoft Word […] With this feature, an infinite number of monkeys will analyze your writing and present you with useless grammar complaints while not alerting you to actual grammatical errors because computers don’t understand grammar. Sure, it sounds great on a box—or a promotional Web site—but anyone who knows, knows that grammar checking is a sham. Just say no.” (Jason Snell), “Computer grammar checking really is terrible. […] The things they are good at, like spotting the occasional the the typing error, are very easy there are very few of them. For the most part, accepting the advice of a computer grammar checker on your prose will make it much worse, sometimes hilariously incoherent. If you want an amusing way to whiling away a rainy afternoon, take a piece of literary prose you consider sublimely masterful and run the Microsoft Word™ grammar checker on it, accepting all the suggested changes.” (Geoffrey K. Pullum, cited by Wikipedia), “My take is that we should encourage students to spell check and revise accordingly, but skip the grammar check and proofread instead.” (Mark Pennington). One of the most important improvements of the last few Microsoft Office versions was lowering the “sensitivity” of the grammar checker, responding to customer feedback (source).
In the next few examples I will show how can we make more precise grammar checking:
First rule: we don’t need to catch all mistakes. In fact, we cannot catch all mistakes. We have got only “monkeys”, and often debatable and controversial concepts about grammatical correctness.
Example 1. Capitalization
The following Lightproof rule searches the sentence beginning lower-case letters, and suggests upper-case ones:
^([a-z]) -> =\1.upper() # Missing capitalization?
Unfortunately, there will be many false alarms, especially after abbreviations, because Lightproof has a very simple default sentence boundary detection based on only the paragraph beginning, and sentence ending punctuation (full stop, exclamation mark and question mark). We can check the previous word for abbreviations by a fast Python regex object called abbrev:
^([a-z]) <- not abbrev.search(word(-1)) ->
=\1.upper() # Missing capitalization?
[code]
# pattern matching for common English abbreviations
abbrev = re.compile("(?i)\b([a-z]|acct|approx|\
appt|apr|apt|assoc|asst|aug|ave|avg|co(nt|rp)?|\
ct|dec|defn|dept|dr|eg|equip|esp|est|etc|excl|\
ext|feb|fri|ft|govt?|hrs?|ib(id)?|ie|in(c|t)?|\
jan|jr|jul|lit|ln|mar|max|mi(n|sc)?|mon|Mrs?|\
mun|natl?|neg?|no(rm|s|v)?|nw|obj|oct|org|orig|\
pl|pos|prev|proj|psi|qty|rd|rec|rel|reqd?|resp|\
rev|sat|sci|se(p|pt)?|spec(if)?|sq|sr|st|subj|\
sun|sw|temp|thurs|tot|tues|univ|var|vs)\.")
The sentence segmentation is better, but not enough for a non-intrusive grammar checker (see also the similar decision of Raphael Mudge, author of the more sophisticated and resource-intensive AtD grammar checker here). We will limit the default checking only for paragraph capitalization, more precisely, checking for the first sentence of a paragraph. The difference is important: lower-case list items seem paragraphs for grammar checker clients of LibreOffice, so we check only the paragraphs with more sentences:
^([a-z]) <- re.search("^[a-z].*[.?!] [A-Z]", TEXT)
and not abbrev.search(TEXT) -> = \1.upper()
# Missing capitalization?
(The string variable TEXT contains the full text of the paragraph.)
Second rule: we have to limit false alarms to zero or near zero.
Example 2. Article a/an
The choice of “a” or “an” is determined by phonetic rules and in some cases, also spelling conventions, see Wikipedia. We have to care about the non-standard pronunciation and writing, too, like the form “an HTML” where the letter H pronounced as [ˈheɪtʃ] (see Wikipedia and BBC), and the rare, but similarly allowed spelling conventions: “an hotel”, “an historic” etc. A relevant Lightproof rule to test the “a”:
# pattern "vow" matches words beginning with vowels:
vow [aeiouAEIOU]\w*
a {vow} <- {vow} <> {vow}.upper() and not
({vow} in aA or {vow}.lower() in aA)
and spell({vow}) -> an {vow} # Bad article?
[code]
aA = set(["eucalypti", "eucalyptus", "Eucharist", "Eucharistic",
"euchre", "euchred", "euchring", "Euclid", "euclidean", "Eudora",
"eugene", "Eugenia", "eugenic", "eugenically", "eugenicist",
...])
One of the most interesting elements of the condition is the final spelling dictionary lookup
by the function spell(): this step limits the grammar checking for the known words. Missing words from the exception list (here: “aA”) and from the spelling dictionary won’t result false alarms, for example for the expression “a uremic” or the rare “a usuress”.
Third rule: Don’t hurt people unnecessarily.
Example 3. Spacing
Instead of annoying multiple spaces, like
" +" -> " " # Remove repeating spaces or use tabulators/styles for formatting.
it’s better to check only double (maybe triple) spaces between words. There is living typewriter tradition in the digital age among the users of word processors, too, see sentence spacing with double spaces. So the proposed grammar checker has got three options for spacing: a default option for word spacing, and two optional for sentence spacing and the bad positioning with multiple spaces.
Example 4. Grammar checking based on detailed language data
Recent English module contains only the following example for morphological analysis:
([Tt])his {abc} <- option("grammar") and morph({abc}, "Ns") ->
\1hese {abc}\n\1his, {abc} # Did you mean:
There are several things here to limit false alarms. This is an optional rule (see the option(“grammar”) condition). The morph() function searches unambiguously plural nouns (“Ns”) using Hunspell and language data of Hunspell dictionaries, and the rule checks only lower-case words after “This” or “this”, so the likely bad expression “this mice” will be detected, but not in the “Why is this Mice of Men a challenged book?”. Extending the English dictionary of LibreOffice with part-of-speech and morphological data will help to add more sophisticated grammar checking rules, for example with conversion of the huge rule set of LanguageTool development.
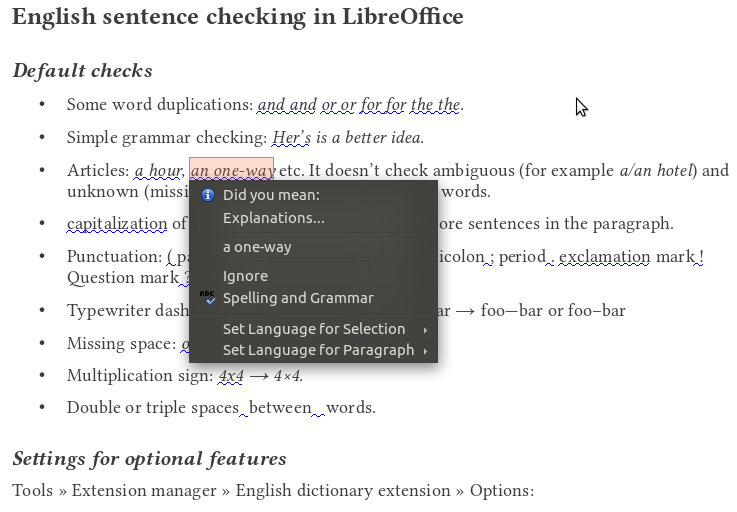
Other concept of sentence checking for LibreOffice is to provide optional tools for proofreading, pre-press formatting and desktop publishing. Not so precise grammar checking is one of these tools, eg. the option “capitalization” of the suggested grammar checker of LibreOffice extends the checking of the capitalization for all sentences, not only for the first ones in the paragraphs.
Az OpenOffice.org kiegészítők elérhetetlensége miatt (ismételt betöltés után jelentkezik be sokszor csak az oldal) a magyar mondatellenőrző (Lightproof magyar modul) elérhetővé vált a LibreOffice kísérleti bővítménytárában is. További leírás a magyar mondatellenőrző legutóbbi kiadásáról, és a LibreOffice bővítménytáráról.
Elkészült a nyílt forráskódú magyar nyelvi ellenőrző javított, bővített kiadása, ami most már LibreOffice alatt is menti a beállításait. Az új kiadás többek közt figyelmeztet az olyan nagy médiafigyelmet kapott nyelvi és helyesírási hibákra is, mint „áld meg” és „jó kedvel”, vagy „Budapest Liszt Ferenc Nemzetközi Repülőtér”. A kiegészítő az Eszközök» Kiterjesztéskezelő ablak Hozzáadás gombjával telepíthető. Telepítés után indítsuk újra a programot a gyorsindítóból is kilépve. A működést és az újdonságokat tesztdokumentum segítségével is ellenőrizhetjük.
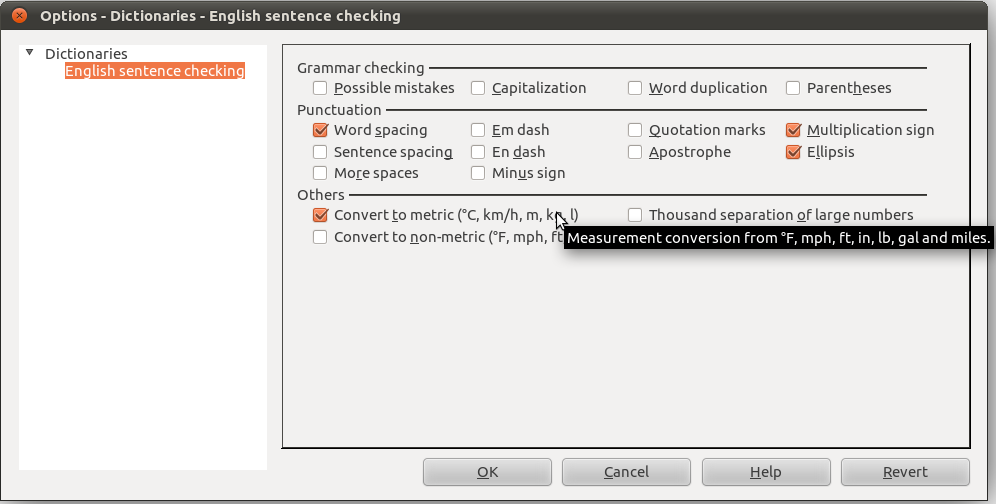
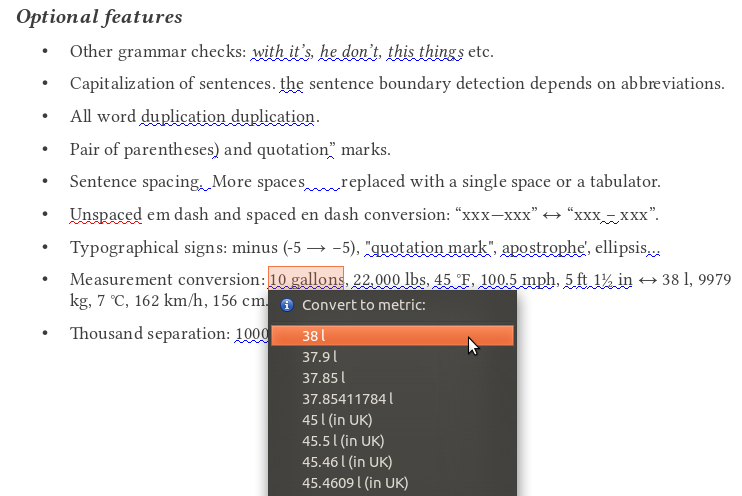
 Az első szembetűnő változás (lásd a mellékelt képre kattintva), hogy bővült az ellenőrző beállítófelülete (ami az Eszközök» Beállítások» Nyelvi beállítások» Magyar nyelvi ellenőrzés menüponton keresztül, és az Eszközök» Kiterjesztéskezelő» Lightproof hu_HU kiválasztása, és a megjelenő Beállítások gomb megnyomásával is elérhető). Az egyik legérdekesebb új korrektúrázási lehetőség az ismertebb angolszász mértékegységek átváltásának felkínálása. Az új opciók lehetővé teszik az olyan ellenőrzések kikapcsolását, amelyek a LibreOffice fejlett Graphite betűkészletei, a Linux Libertine G és Biolinum G használata esetén feleslegesek (ilyen az idézőjelek, gondolatjel, három pont, mínuszjel cseréje, ami a betűkészlet szintjén automatikusan végbemegy vagy mehet, bővebben lásd a Kiadványszerkesztés LibreOffice Writer szövegszerkesztővel jegyzetben).
Az első szembetűnő változás (lásd a mellékelt képre kattintva), hogy bővült az ellenőrző beállítófelülete (ami az Eszközök» Beállítások» Nyelvi beállítások» Magyar nyelvi ellenőrzés menüponton keresztül, és az Eszközök» Kiterjesztéskezelő» Lightproof hu_HU kiválasztása, és a megjelenő Beállítások gomb megnyomásával is elérhető). Az egyik legérdekesebb új korrektúrázási lehetőség az ismertebb angolszász mértékegységek átváltásának felkínálása. Az új opciók lehetővé teszik az olyan ellenőrzések kikapcsolását, amelyek a LibreOffice fejlett Graphite betűkészletei, a Linux Libertine G és Biolinum G használata esetén feleslegesek (ilyen az idézőjelek, gondolatjel, három pont, mínuszjel cseréje, ami a betűkészlet szintjén automatikusan végbemegy vagy mehet, bővebben lásd a Kiadványszerkesztés LibreOffice Writer szövegszerkesztővel jegyzetben).
 A magyar köznyelvben nehezen értelmezhető (az iskolai tananyag részét nem képező), ezért átváltásra felkínált mértékegységek a Fahrenheit-fok (°F), mérföld, yard, láb, hüvelyk, gallon, pint, font súly („font súlyú” alakban írva). Az átváltást és a felkínált különböző kerekítéseket a Libreoffice CONVERT_ADD és ROUND táblázatkezelő függvényei végzik el, a toldalékolást (pl. „15 mérfölddel” → 24 kilométerrel) pedig a Hunspell program. Érdekességként, a fejlesztés kapcsán a gallon váltószámának pontosítására is sor került a LibreOffice forráskódjában (l. programfolt, az eltérés 0,02% volt). A mértékegységek felismerése alapértelmezett, de a nyelvi ellenőrző Mértékegységek beállításával kikapcsolható. (Hasonló mértékegység-váltó a Microsoft Office-ban is rendelkezésre állt, de az ezt megvalósító, korábban nagy újdonságként beharangozott intelligens címkéket száműzték a Microsoft Office 2010-ből. A helyére szánt, a kijelölt szövegrészek helyi menüjén keresztül elérhető mértékegység-váltó gyakorlatilag el van rejtve a felhasználók elől körülményes használata miatt.)
A magyar köznyelvben nehezen értelmezhető (az iskolai tananyag részét nem képező), ezért átváltásra felkínált mértékegységek a Fahrenheit-fok (°F), mérföld, yard, láb, hüvelyk, gallon, pint, font súly („font súlyú” alakban írva). Az átváltást és a felkínált különböző kerekítéseket a Libreoffice CONVERT_ADD és ROUND táblázatkezelő függvényei végzik el, a toldalékolást (pl. „15 mérfölddel” → 24 kilométerrel) pedig a Hunspell program. Érdekességként, a fejlesztés kapcsán a gallon váltószámának pontosítására is sor került a LibreOffice forráskódjában (l. programfolt, az eltérés 0,02% volt). A mértékegységek felismerése alapértelmezett, de a nyelvi ellenőrző Mértékegységek beállításával kikapcsolható. (Hasonló mértékegység-váltó a Microsoft Office-ban is rendelkezésre állt, de az ezt megvalósító, korábban nagy újdonságként beharangozott intelligens címkéket száműzték a Microsoft Office 2010-ből. A helyére szánt, a kijelölt szövegrészek helyi menüjén keresztül elérhető mértékegység-váltó gyakorlatilag el van rejtve a felhasználók elől körülményes használata miatt.)
Az új mondat-ellenőrzési szabályok számos durva helyesírási hiba felismerésében segítenek: ilyen hibák a „halott róla”, „el kellet mennie”, hord el az irhád!, küzd vissza magad!, vagy a köztársasági elnök újévi köszöntőjének hivatalos átiratából elhíresült tévesztések, „Isten, áld meg a magyart! Jó kedvel, bőséggel!”. (A Himnusz sorai helyesen: „Isten, áldd meg a magyart / Jó kedvvel, bőséggel”!)
A ferihegyi Liszt Ferenc nemzetközi repülőtér jogszabályban rögzített neve, a Budapest Liszt Ferenc Nemzetközi Repülőtér több hibát is tartalmaz: a repülőterek nevének köznévi tagjait kisbetűvel írjuk (AkH. 190.), a helység- és helynevet tartalmazó felsorolásokat pedig vesszővel választjuk el (AkH. 298.): Budapest, Liszt Ferenc nemzetközi repülőtér, vagy Liszt Ferenc nemzetközi repülőtér, Budapest. A Földrajzinév-bizottság elvetette a magyartalan, illetve helyesírási hibás nevet, földrajzi helyesírási hibaként kiemelve még a Ferihegy védett földrajzi név elhagyását (ami jelenleg is érvényes földrajzi név, Budapest egyik városrésze), helyette a kormány javaslatát maximálisan tiszteletben tartva a Liszt Ferenc Nemzetközi Repülőtér, Budapest–Ferihegy elnevezést javasolta. A megfelelő indoklást is tartalmazó határozat azonban nem készülhetett el, mert a bizottság több tagját, köztük az elnököt felmentették, többeket elbocsátottak a munkahelyükről, köztük Mikesy Gábor nyelvészt, az OSOR.eu-n is szereplő Vingis szabad szoftveres állami térinformatikai rendszer egyik fejlesztőjét. A két hivatalos magyarázat szerint azért, mert a minisztériumoktól delegált bizottsági tagok nem kérték ki a tárcák véleményét, vagy azért, mert nem támogatták a „kormány kinyilvánított és egyértelmű kérését”. (Azóta az elbocsátott munkatársak helyzete valamelyest rendeződött, l. Dutkó Andrással, a bizottság volt elnökével készült interjút, ami a bizottságot ért támadásokra is reagál.) A Földrajzinév-bizottság jogkörét külön kormányrendeletben korlátozták, hogy „kiemelt közérdek” esetén a magyar nyelv védelme másodlagos szempont lehessen. A rendelet egyben felmentette a bizottság tagjait, illetve minimalizálta a leendő új tagság létszámát is. Az abszurd ügy hátterét jól megvilágítja a Térinformatika-online cikke, amihez csak annyit lehet hozzátenni, hogy mi okozta az eredeti hibás javaslatot: a kormánypárti javaslattevők a jogszabályokban szereplő „Budapest Ferihegy Nemzetközi Repülőtér” névben a Budapest Ferihegyet (a repülőtér nemzetközi nevét) „Budapest Liszt Ferenccel” helyettesítették. A Földrajzinév-bizottság sárba tiprásával megszületett törvény a joganyagban szereplő különböző meghatározásokat, köztük a „Budapest (Ferihegy)”, „Ferihegy”, „Ferihegyi repülőtér”, „Ferihegyi nemzetközi kereskedelmi repülőtér” elnevezéseket egységesen az új, a bizottság által 20:1 arányban leszavazott névre cserélte le. A magyar nyelvi ellenőrző a „Liszt Ferenc nemzetközi repülőtér”, „ferihegyi Liszt Ferenc nemzetközi repülőtér”, „Ferihegy”, valamint a „Budapest, Liszt Ferenc nemzetközi repülőtér” elnevezések használatát javasolja a nyelvi szakértők által egyöntetűen elutasított hibás megnevezés helyett.
A magyar nyelvi ellenőrző mögött álló Lightproof keretrendszert afrikaans, arab, francia (Grammalecte) és orosz nyelvi ellenőrzők készítésénél is felhasználták. A keretrendszer és a magyar nyelvi ellenőrző modul fejlesztése az FSF.hu Alapítvány támogatásával valósult meg.