 Competitive grammar checking would be a nice improvement for LibreOffice. Supported by FSF.hu Foundation, Hungary, I have made two sentence checking patches to the English and Hungarian dictionary extensions of LibreOffice, based on the Lightproof Python UNO environment: see the related issue, the description and the standalone extensions. [Update: source code, Lightproof editor extension]
Competitive grammar checking would be a nice improvement for LibreOffice. Supported by FSF.hu Foundation, Hungary, I have made two sentence checking patches to the English and Hungarian dictionary extensions of LibreOffice, based on the Lightproof Python UNO environment: see the related issue, the description and the standalone extensions. [Update: source code, Lightproof editor extension]
One of the main concepts of “sentence checking” is to break the bad habit of grammar checkers, the annoyingly frequent false alarms. Reporting all potential (but usually not) problems isn’t able to replace proofreading, but very frustrating: “the most useless feature ever added to Microsoft Word […] With this feature, an infinite number of monkeys will analyze your writing and present you with useless grammar complaints while not alerting you to actual grammatical errors because computers don’t understand grammar. Sure, it sounds great on a box—or a promotional Web site—but anyone who knows, knows that grammar checking is a sham. Just say no.” (Jason Snell), “Computer grammar checking really is terrible. […] The things they are good at, like spotting the occasional the the typing error, are very easy there are very few of them. For the most part, accepting the advice of a computer grammar checker on your prose will make it much worse, sometimes hilariously incoherent. If you want an amusing way to whiling away a rainy afternoon, take a piece of literary prose you consider sublimely masterful and run the Microsoft Word™ grammar checker on it, accepting all the suggested changes.” (Geoffrey K. Pullum, cited by Wikipedia), “My take is that we should encourage students to spell check and revise accordingly, but skip the grammar check and proofread instead.” (Mark Pennington). One of the most important improvements of the last few Microsoft Office versions was lowering the “sensitivity” of the grammar checker, responding to customer feedback (source).
In the next few examples I will show how can we make more precise grammar checking:
First rule: we don’t need to catch all mistakes. In fact, we cannot catch all mistakes. We have got only “monkeys”, and often debatable and controversial concepts about grammatical correctness.
Example 1. Capitalization
The following Lightproof rule searches the sentence beginning lower-case letters, and suggests upper-case ones:
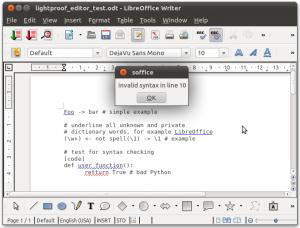
^([a-z]) -> =\1.upper() # Missing capitalization?
Unfortunately, there will be many false alarms, especially after abbreviations, because Lightproof has a very simple default sentence boundary detection based on only the paragraph beginning, and sentence ending punctuation (full stop, exclamation mark and question mark). We can check the previous word for abbreviations by a fast Python regex object called abbrev:
^([a-z]) <- not abbrev.search(word(-1)) ->
=\1.upper() # Missing capitalization?
[code]
# pattern matching for common English abbreviations
abbrev = re.compile("(?i)\b([a-z]|acct|approx|\
appt|apr|apt|assoc|asst|aug|ave|avg|co(nt|rp)?|\
ct|dec|defn|dept|dr|eg|equip|esp|est|etc|excl|\
ext|feb|fri|ft|govt?|hrs?|ib(id)?|ie|in(c|t)?|\
jan|jr|jul|lit|ln|mar|max|mi(n|sc)?|mon|Mrs?|\
mun|natl?|neg?|no(rm|s|v)?|nw|obj|oct|org|orig|\
pl|pos|prev|proj|psi|qty|rd|rec|rel|reqd?|resp|\
rev|sat|sci|se(p|pt)?|spec(if)?|sq|sr|st|subj|\
sun|sw|temp|thurs|tot|tues|univ|var|vs)\.")
The sentence segmentation is better, but not enough for a non-intrusive grammar checker (see also the similar decision of Raphael Mudge, author of the more sophisticated and resource-intensive AtD grammar checker here). We will limit the default checking only for paragraph capitalization, more precisely, checking for the first sentence of a paragraph. The difference is important: lower-case list items seem paragraphs for grammar checker clients of LibreOffice, so we check only the paragraphs with more sentences:
^([a-z]) <- re.search("^[a-z].*[.?!] [A-Z]", TEXT)
and not abbrev.search(TEXT) -> = \1.upper()
# Missing capitalization?
(The string variable TEXT contains the full text of the paragraph.)
Second rule: we have to limit false alarms to zero or near zero.
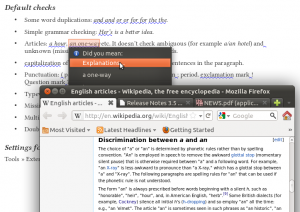
Example 2. Article a/an
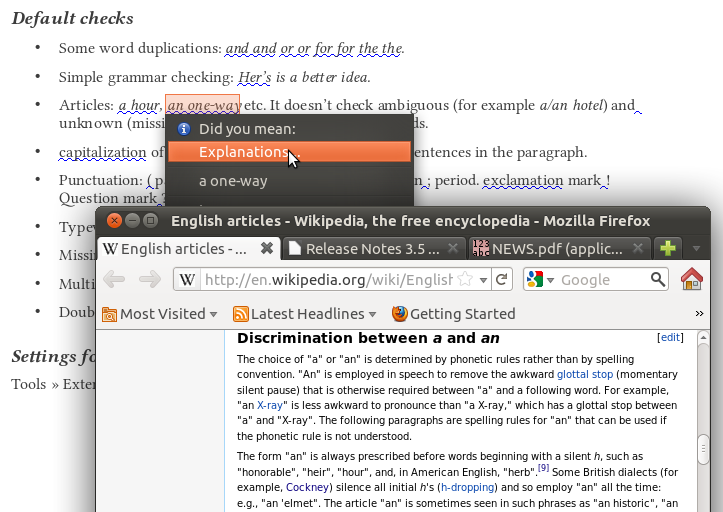
The choice of “a” or “an” is determined by phonetic rules and in some cases, also spelling conventions, see Wikipedia. We have to care about the non-standard pronunciation and writing, too, like the form “an HTML” where the letter H pronounced as [ˈheɪtʃ] (see Wikipedia and BBC), and the rare, but similarly allowed spelling conventions: “an hotel”, “an historic” etc. A relevant Lightproof rule to test the “a”:
# pattern "vow" matches words beginning with vowels:
vow [aeiouAEIOU]\w*
a {vow} <- {vow} <> {vow}.upper() and not
({vow} in aA or {vow}.lower() in aA)
and spell({vow}) -> an {vow} # Bad article?
[code]
aA = set(["eucalypti", "eucalyptus", "Eucharist", "Eucharistic",
"euchre", "euchred", "euchring", "Euclid", "euclidean", "Eudora",
"eugene", "Eugenia", "eugenic", "eugenically", "eugenicist",
...])
One of the most interesting elements of the condition is the final spelling dictionary lookup
by the function spell(): this step limits the grammar checking for the known words. Missing words from the exception list (here: “aA”) and from the spelling dictionary won’t result false alarms, for example for the expression “a uremic” or the rare “a usuress”.
Third rule: Don’t hurt people unnecessarily.
Example 3. Spacing
Instead of annoying multiple spaces, like
" +" -> " " # Remove repeating spaces or use tabulators/styles for formatting.
it’s better to check only double (maybe triple) spaces between words. There is living typewriter tradition in the digital age among the users of word processors, too, see sentence spacing with double spaces. So the proposed grammar checker has got three options for spacing: a default option for word spacing, and two optional for sentence spacing and the bad positioning with multiple spaces.
Example 4. Grammar checking based on detailed language data
Recent English module contains only the following example for morphological analysis:
([Tt])his {abc} <- option("grammar") and morph({abc}, "Ns") ->
\1hese {abc}\n\1his, {abc} # Did you mean:
There are several things here to limit false alarms. This is an optional rule (see the option(“grammar”) condition). The morph() function searches unambiguously plural nouns (“Ns”) using Hunspell and language data of Hunspell dictionaries, and the rule checks only lower-case words after “This” or “this”, so the likely bad expression “this mice” will be detected, but not in the “Why is this Mice of Men a challenged book?”. Extending the English dictionary of LibreOffice with part-of-speech and morphological data will help to add more sophisticated grammar checking rules, for example with conversion of the huge rule set of LanguageTool development.
Other concept of sentence checking for LibreOffice is to provide optional tools for proofreading, pre-press formatting and desktop publishing. Not so precise grammar checking is one of these tools, eg. the option “capitalization” of the suggested grammar checker of LibreOffice extends the checking of the capitalization for all sentences, not only for the first ones in the paragraphs.
Feature lists of the recent English module
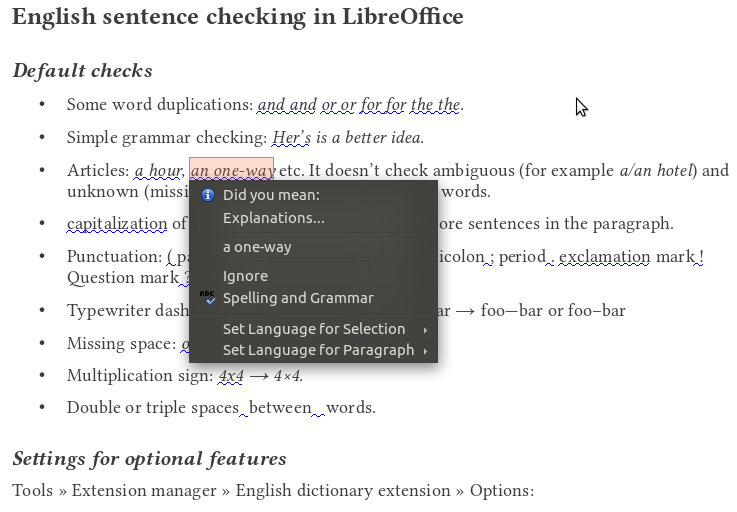
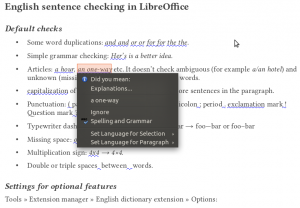
Default checks
- Punctuation (unnecessary spaces before punctuation, missing spaces after punctuation, hyphen instead of n-dash, real double quotation marks and multiplication sign)
- A/an article (with the described improvements)
- Word spacing (not sentence spacing)
- Paragraph capitalization (unwitting paragraph breaks)
- Simple word duplication (and and, or or, for for, the the)
- Longer explanations, using relevant Wikipedia articles (see first screenshot)
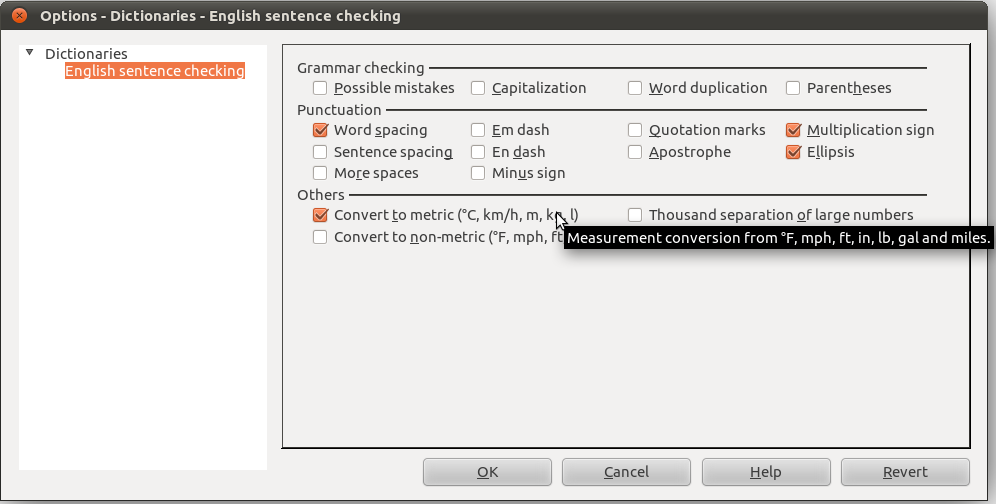
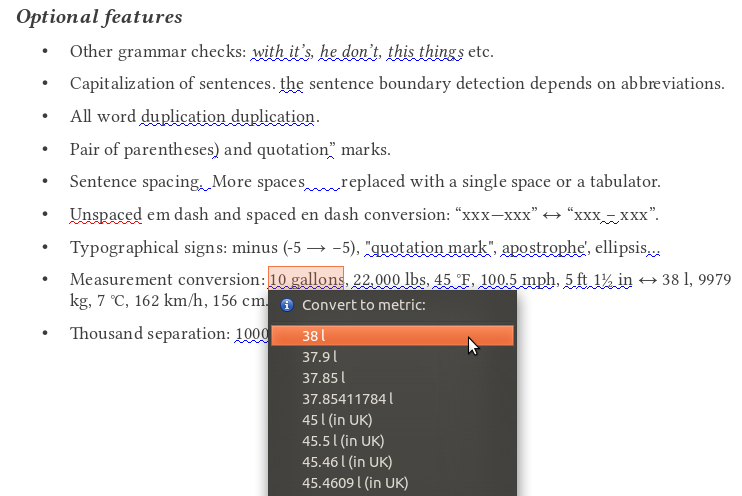
Optional features
- More grammar checks (a few examples using Hunspell morphological analyzer and the English dictionary)
- More punctuation checks (n-dash/m-dash, unpaired quotation marks and parentheses, typographical apostrophe and ellipsis)…
- Measurement conversion (lb/kg, mph/km/h, °F/°C, ft/yd/in/m/cm/mm, mile/km, gal/pint/l)
- Thousand separation (common or ISO)
- Sentence capitalization
- Other word duplication
- Sentence spacing (double spaces)
- Formatting with spaces (more than 3 spaces)
- Settings (a little hidden yet): in Tools » Extension manager… choose “English spelling etc. dictionaries” extension and click on its Options button.


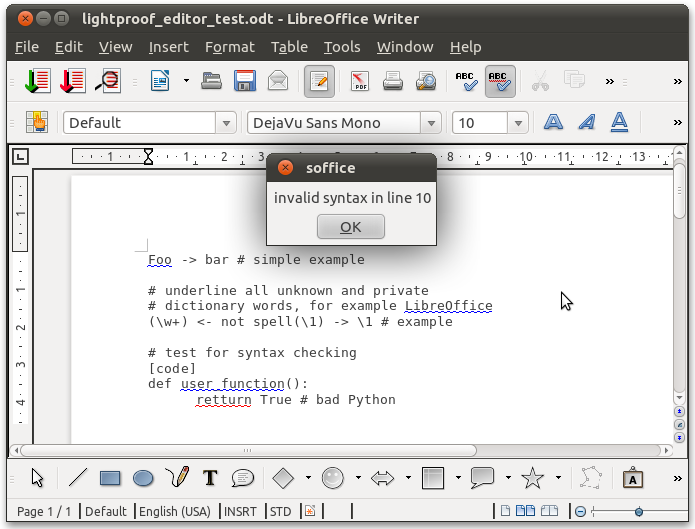
Features of Lightproof rule editor
- LibreOffice extension, downloading, description
- Special grammar checking component + LibreOffice toolbar for rule compiling and debugging
- Run-time compilation and update of its grammar checking component
- Debugging of user code (rule conditions and Python user functions)












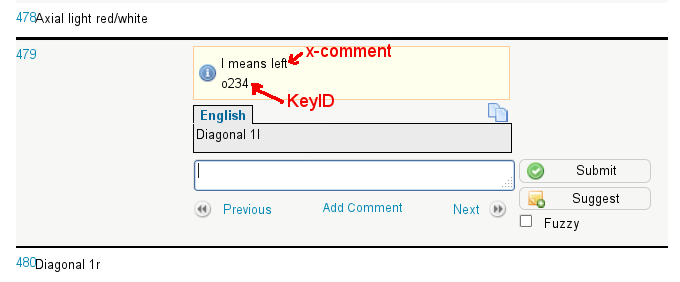
 When I arrived in Hamburg I did not know exactly what I would hack on. Something localization related was in my mind. Then I decided that I would like to solve an easy hack which has not been picked by anyone for 18 months, yet it is important from the localization point of view. In source code of UI strings (both in vcl resources, and in xml config files) it is possible to add comments to English UI string in order to explain or disambiguate them. These comments have a special language code: x-comment. Until now tooling ignored these comments, they were not extracted to sdf/po files, so they were little of use to translators. There are not many x-comments in the code, but it is no wonder. It would have not made sense to write comments that nobody would ever see. I patched l10ntools in master, so from now on x-comments are extracted, and will be there in the po files.
When I arrived in Hamburg I did not know exactly what I would hack on. Something localization related was in my mind. Then I decided that I would like to solve an easy hack which has not been picked by anyone for 18 months, yet it is important from the localization point of view. In source code of UI strings (both in vcl resources, and in xml config files) it is possible to add comments to English UI string in order to explain or disambiguate them. These comments have a special language code: x-comment. Until now tooling ignored these comments, they were not extracted to sdf/po files, so they were little of use to translators. There are not many x-comments in the code, but it is no wonder. It would have not made sense to write comments that nobody would ever see. I patched l10ntools in master, so from now on x-comments are extracted, and will be there in the po files.