A 2018. május 12-i Szabad szoftver konferencián került bejelentésre, és most megjelent az utóbbi évek legnagyobb magyar nyelvi vonatkozású szabad szoftveres fejlesztésének eredménye, a Szabad magyar szótár 1.7-es változata. A magyar szóalaktan leírását is tartalmazó szótár minden eddiginél pontosabb magyar helyesírás-ellenőrzést nyújt a LibreOffice, a Google Chrome, Mozilla Firefox, Scribus vagy akár az olyan kereskedelmi programok, mint a Google Dokumentumok, Adobe InDesign és macOS felhasználói számára.
A béta kiadások sokezres javításaihoz és szókincsbővítéséhez képest a végleges kiadás további 13 ezer szó-, morféma- és betűhatárra vonatkozó szótári bejegyzéssel bővült, amely lehetővé tette az első helyesen működő magyar betűrendbe soroló szabad szoftver, a Zsort elkészítését is.
A nyelvi fejlesztések a nyomdai minőségű automatikus magyar elválasztás megvalósításával folytatódhatnak a jövő évben. Kérjük, hogy ehhez adója 1%-ának felajánlásával segítse az FSF.hu Alapítványt, a magyar nyelvi fejlesztések fő támogatóját! A fejlesztések részletei:
Zsort 1.0
A Zsort (ejtsd zé-szort vagy zsort) a Szabad magyar szótár 1.7-es változatán és a Hunspell helyesírás-ellenőrzőn és morfológiai elemzőn, valamint a GNU sorton alapuló gAWK program, amely a következő előnyös tulajdonságokkal rendelkezik a helyesiras.MTA.hu akhsort webes betűrendbe soroló szolgáltatásához képest: (1) a felbontandó „ál-többjegyű” mássalhangzókat minden szótári szó (pl. más|szor) és heurisztikusan felismert összetett szó (pl. adás|szünet|kérés) esetében felismeri (2) 50 szónál több szó is rendezhető vele, akár több millió is (3) nem fagy le több szóból álló kifejezésekre, címekre, hanem helyesen képes azokat is rendezni (4) szabad program, így működése megismerhető, a kód módosítható és szabadon terjeszthető. További előnyei: (5) működése bár a GNU C Library-n (glibc) alapul, nem függ annak legújabb javításaitól (Koblinger Egmont javításaival a glibc 2.26 végre az IBM ICU/Unicode CLDR adatbázisához hasonlóan rendezi a kettőzött többjegyű mássalhangzók egyszerűsített alakjait). (6) A kifejezésekre vonatkozó rendezési szabályok mellett javítja a glibc különleges hibáját is, a zsanér, zsáner és a hasonlóan azonos alakú, csak a hosszú magánhangzók helyében eltérő szóalakok sorrendjének felcserélését is.
A Zsortot 4 millió különböző szóalakon összehasonlítva az IBM ICU/Unicode CLDR magyar rendezési algoritmusával, azonnal nyilvánvalóvá válik a különbség: 25 ezer szónak változik meg a pozíciója, amennyiben nem tekintünk minden cs, dz, dzs, gy, ly, ny, sz, ty, zs, ccs, ddzs, ggy, lly, nny, ssz, tty és zzs jelsorozatot automatikusan (kettőzött) többjegyű mássalhangzónak, hanem megvizsgáljuk a szavak tövét és toldalékolását, és annak megfelelően döntünk a szavak sorrendjéről, például a község, tizennyolc stb. szavak nem zs, vagy kettőzött ny betűt tartalmaznak. 5 további szó a 25 ezerből (sorkezdő mínuszjel jelöli a régi, és pluszjel jelöli a javított pozíciót):
--- szavak.icu 2018-05-17 15:36:53.958051037 +0200
+++ szavak.zsort 2018-05-17 15:37:07.209816339 +0200
@@ -1331,8 +1331,8 @@
ablakmélyedéseknél
ablakmélyedési
ablakmélyedésig
-ablakmélyedést
ablakmélyedésszerű
+ablakmélyedést
ablakmenedzserek
ablakmenü
ablakméret
...
zsoldosseregre
zsoldosseregünk
zsoldosseregünkkel
+zsoldosszellem
+Zsoldosszerenádot
+Zsoldosszerenádra
zsoldost
Zsoldost
Zsoldostáborban
@@ -4039942,9 +4039945,6 @@
zsoldosvezérről
zsoldosvezért
zsoldosvilág
-zsoldosszellem
-Zsoldosszerenádot
-Zsoldosszerenádra
zsoldosztás
zsoldosztásra
zsoldot
@@ -4040806,11 +4040806,11 @@
zsongásról
zsongássá
zsongással
+zsongásszerű
zsongást
zsongású
zsongásuk
zsongásunkat
-zsongásszerű
zsongat
zsongatja
zsongatják
A teljes lista itt tekinthető meg, a program félezer soros, a teszteseteket is tartalmazó forráskódja pedig itt.
Szabad magyar szótár 1.7.
A szótárfejlesztés kiemelt célja a legnépszerűbb, a magyar nyelv támogatásában is élen járó szabad irodai programcsomag, a LibreOffice, ahol a szótár az alapja a magyar szinonimaszótárban és a nyelvhelyesség-ellenőrzőben használt szótövezésnek, toldalékolásnak és morfológiai elemzésnek is, valamint az új toldalékoló felhasználói szótárnak. A legújabb szótár is úton van a LibreOffice 6.1 és 6.0-s változatába. A bevezetőben is felsorolt, Hunspell helyesírás-ellenőrzőt tartalmazó programok is a Szabad magyar szótár felhasználói, ahogy ez a szótár az alapja a Magyar Tudományos Akadémia helyesiras.mta.hu Helyes-e így? néven futó szolgáltatásának is. A Szabad magyar szótár bár nem helyesírási tanácsadó szolgáltatások üzemeltetésére készült, a legutóbbi fejlesztésekkel közelebb került ehhez: szótára, valamint a Hunspell program több ezer szótári szó esetében támogatja már a kiejtés alapú javaslattevést, pl. Niccse → Nietzsche, valamint a tipikus egybeírási hibák felismerését és pontos javítását: idegenszavakat → idegen szavakat, rákövetkező → rá következő, csirkefarhát → csirke far-hát stb.
Az új magyar helyesírási reform és a magyar szókincs változásainak követéséről, illetve a kapcsolódó fejlesztésekről részletesen szólnak a béta kiadások hírei.
A szótár- és programhibák a LibreOffice és a magyar fordítók OpenScope felületének hibabejelentője mellett most már a Szabad magyar szótár GitHub projektoldalán is bejelenthetők.
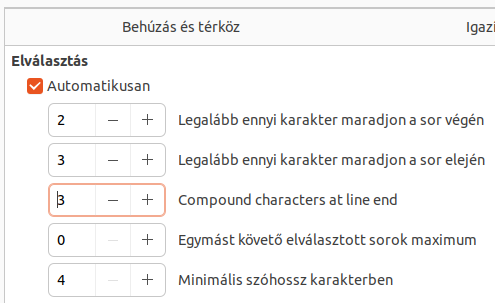
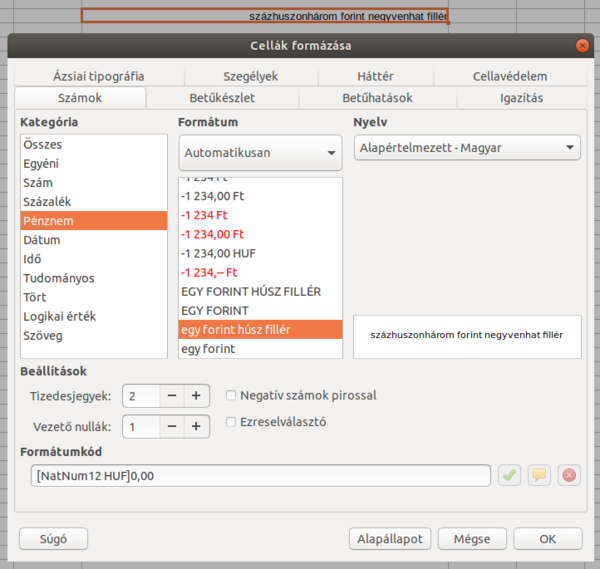
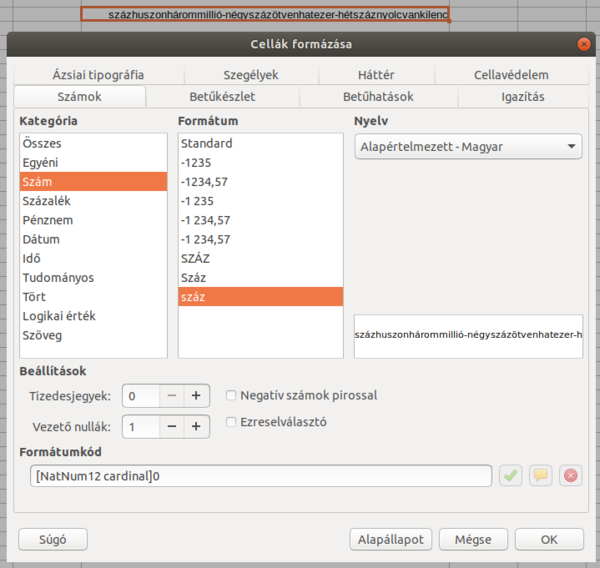

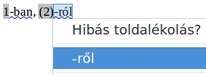
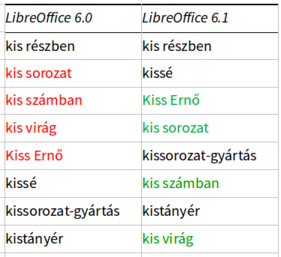 A LibreOffice 6.1 a következő pontokon javítja a szavak, bekezdések és cellák szövegtartalmának magyar betűrendbe sorolását a
A LibreOffice 6.1 a következő pontokon javítja a szavak, bekezdések és cellák szövegtartalmának magyar betűrendbe sorolását a