Hyphenation in cells and shapes was fixed a few days ago for Catalan (for example, paral·lel » paral-lel, instead of parall-lel), Hungarian (eg. asszonnyal » asz-szony-nyal instead of az-szoy-nyal) and Dutch (eg. omaatje » oma-tje instead of omaa-atje, cafeetje » café-tje instead of cafeét-je). Swedish, Norwegian and partly Dutch need only hyphenation dictionary extension to support non-standard hyphenation in LibreOffice, Greek and Dutch need also Writer and Calc/Draw (editeng) development to support the alternation after the hyphenation break. More information: bug 63711 (closed), bug 42383 (open), Hyphen library (see tests/unicode.* example for non-standard hyphenation patterns of Dutch, Greek, Norwegian and Swedish).

Kategória: english
Improvements in local help
I would like to show you two recent improvements in local help system of LibreOffice.
Indentation and syntax highlighting of Basic code examples
Basic code examples were hard to read in LibreOffice help, because code blocks were not indented. Also, people got used to syntax highlighting in editors.
By LibreOffice 4.0 I made the code examples indented with some scripts and a bit of manual work. I also tweaked help-to-wiki conversion script, so online WikiHelp of LibreOffice 4.0 will feature syntax highlighting of Basic code examples.
For the local help content, my idea was to re-use SyntaxHighlighter class from svtools in help compiler, so we could add the colors build-time, without modifying the source and create work for translators. Dávid Vastag, a university student, who worked with Novell Hungary as a trainee, helped me to implement this feature in help compiler. The following screenshots show how an example Basic code is rendered in different versions of LibreOffice help.



Size reduction of local help
When I studied help XML files, I noticed that many of the tags and attributes are not needed run-time. Some of them are even completely obsolete, and are not needed at all. However a mass clean-up in the source would not be desirable, it can cause extra work for translators for example. My idea was to apply a stylesheet to each file in the help compilation phase. I created compact.xsl, which removes comments, whitespace, and unnecessary tags and attributes. The size of en-US Windows MSI help pack decreased from 7.83 MB to 5.14 MB – 34% less!
Logo for template development

The simple programmable vector graphics of LibreOffice 4 is quite useful in OpenDocument template development. The templates.libreoffice.org site has got a new section called LibreLogo, and some interesting new Logo related templates:
Logo for desktop publishing
In the previous blog post there was a Christmas postcard created by the help of LibreLogo, the simplified programming interface of LibreOffice Writer for graphic design. Now I will show more DTP-related examples: typesetting chessboards with high print quality in LibreOffice 4.0, and a special Christmas ball. (It will be possible to test these examples in the next beta version of LibreOffice 4.0 under Windows, too).
Typesetting chessboards using special chess fonts. This example (see first picture and PDF, ODT with source code) uses a special TrueType font, Chess Merida, filled with characters of the same size (partially combined with black hatched background). The LibreLogo program puts every characters into different text shapes using the LABEL command. The text shapes are grouped by the special PICTURE command of LibreLogo, so the result will be a single grouped shape (use the ungroup icon of the Drawing Object Properties toolbar to remove this grouping). The program asks for the point size of the figures and the positions of the chess figures in chess notation. Decoding of the standard notation is solved by only a few program lines, thanks to the compact Python data structures of LibreLogo.


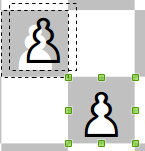
Typesetting chessboards only with standard Unicode characters, by notation or manual positioning. This chessboard drawing program depends only from standard Unicode chess characters (see second picture, and PDF, ODT with source code). To get real white figures from the transparent characters of the Unicode white chess figures the program draws two invisible square shapes for a figure, and put a black chess figure character in white into the background square, and the white chess character into the foreground square by the TEXT commands (see picture). The two squares are grouped by PICTURE. Without the given notation, the program draws a full chessboard, and it’s possible to move the figures to the requested positions manually (frames of the invisible squares allow precise positioning).
Christmas song on a Christmas ball. These beautiful Christmas balls are composed of 5-5 paper stripes. The stripes contain plain and upside-down lines of a Christmas song (English version with instructions: PDF, ODT with source code). The Christmas balls (and the Christmas stars of the previous post) were very popular on the Christmas Fair yesterday, thanks for the nice work of Veronika Bognár and Éva Bozsó.


Logo
![]()
Drawing and programming are fun, and it’s often useful to combine them. The aim of LibreLogo, the new experimental LibreOffice module + Writer toolbar to give an easy, Logo-like, Python based programming environment to the excellent vector graphics of LibreOffice. Here (and in my next posts) I will show examples of LibreLogo usage in school/office environment.
Fine graphics with printing quality. PDF and SVG exports of the OpenDocument format support printing and DTP programs: click on the first picture for the SVG export (Warning! It may halt Firefox 15).



Precise drawing. Turtle moving commands of LibreLogo supports printing measurements, and combining with manual handling of drawing objects in LibreOffice, it can save expensive decorative paper, as for these 3D Christmas stars (made for the local School Christmas fair). PDF, PDF2 (with spirals), ODT (with LibreLogo source).

Fancy, unique documents. This Christmas background created by random snowflakes: Unicode character “❄” (U+2744) with random sizes, positions and angles. The result of the LibreLogo program has been modified (overlapping of snowflakes, title) manually. PDF, ODT (with LibreLogo source).
More information: my LibreOffice conference presentation and a blog post also about LibreLogo from Cor Nouws.
feature/killsdf branch merged
What was SDF and why did we kill it? LibreOffice source code contains translatable content in various file formats. It was desirable to present translatable content to translators in a single file format, so they did not have learn how to edit different file formats. Therefore back in the OpenOffice.org era SDF file format was invented. It was a simple tab separated text file. Localization tools extacted translatable content into SDF file format, and localized SDF files were merged back to source code during the build.
One cannot imagine simpler file format, than a tab separated text. When I translated OpenOffice.org into Hungarian, I built a tool set around it, and translated it happily. But not every translator was a programmer, or capable of using scripts. Translators demanded PO file format, which is a quasi-standard file format for localization in the open source world. Translate Toolkit and Pootle became part of the localization process, en-US SDF file was converted to POT (PO Template) files, and translated PO files were converted back to SDF manually.
When LibreOffice project started, I wanted to amend the process for two reasons.
- Huge SDF files blew the git repository. Git does not work well with large, frequently updated text files.
- Manual conversion from PO to SDF was a tedious job.
Therefore I implemented to store PO files in git, and convert them to SDF automatically during the build. In LibreOffice 3.4 we used po2oo from Translate Toolkit for the back-conversion. In LibreOffice 3.5 po2oo was replaced by po2lo written by Miklos Vajna, which was 30x as fast as po2oo.
But why convert translations from one format to another, why not use PO files directly? This is what was developed in feature/killsdf branch in the past few months. Most of the programming work was done by a young developer, Tamas Zolnai, who was a trainee at Novell Hungary in the summer, and now he is a fellow of FSF.hu Foundation (FSF.hu sponsors his work on LibreOffice). Now localization tools extract translatable content from the source code directly to PO files, and they read PO files directly during the build. SDF files are not generated any more. At the same time localization tools were refactored. Perl scripts have gone. All tools are in C++ now. Further cleanup and optimizations are on the way on master branch. I fixed the last remaining issues after the merge in Munich Hackfest 2012.
Shrinking size of Windows installer
Size of Windows installer of LibreOffice 3.3 – that contained all languages – was 253MB. In LibreOffice 3.4 we managed shrink it significantly, to 197MB. It would have been nice to measure how each cleanup commit contributed to this achievement, but I’m afraid the most important factor was the right setting of compression levels.
Not much have happened since then, we added new languages, new dictionaries, new features, and cleanup continued, but the size of installer remained approximately the same: 198MB for LibreOffice 3.6.0.
However, in LibreOffice 3.7 there will be some improvement in this field. A couple of days ago Istvan Turi – who spent 6 weeks with LibreOffice hacking as a trainee at Novell Hungary – committed a few patches and I also committed one, which removed all language dependent agenda/fax/letter/report and spreadsheet style templates. Approximately 2000 files were removed from git. Even more were removed from installer, because these templates were not localized into all supported languages, so en-US templates were copied for them. Size of installer has been decreased to 185MB, 6.57% less than before.
The good news is that we did not loose functionality here. Localization will be done runtime. Translators can translate strings from these templates in .po files. I bet that many language teams did not know about these templates, now they have the chance to localize them properly.
My hack at Hamburg Hackfest
 When I arrived in Hamburg I did not know exactly what I would hack on. Something localization related was in my mind. Then I decided that I would like to solve an easy hack which has not been picked by anyone for 18 months, yet it is important from the localization point of view. In source code of UI strings (both in vcl resources, and in xml config files) it is possible to add comments to English UI string in order to explain or disambiguate them. These comments have a special language code: x-comment. Until now tooling ignored these comments, they were not extracted to sdf/po files, so they were little of use to translators. There are not many x-comments in the code, but it is no wonder. It would have not made sense to write comments that nobody would ever see. I patched l10ntools in master, so from now on x-comments are extracted, and will be there in the po files.
When I arrived in Hamburg I did not know exactly what I would hack on. Something localization related was in my mind. Then I decided that I would like to solve an easy hack which has not been picked by anyone for 18 months, yet it is important from the localization point of view. In source code of UI strings (both in vcl resources, and in xml config files) it is possible to add comments to English UI string in order to explain or disambiguate them. These comments have a special language code: x-comment. Until now tooling ignored these comments, they were not extracted to sdf/po files, so they were little of use to translators. There are not many x-comments in the code, but it is no wonder. It would have not made sense to write comments that nobody would ever see. I patched l10ntools in master, so from now on x-comments are extracted, and will be there in the po files.
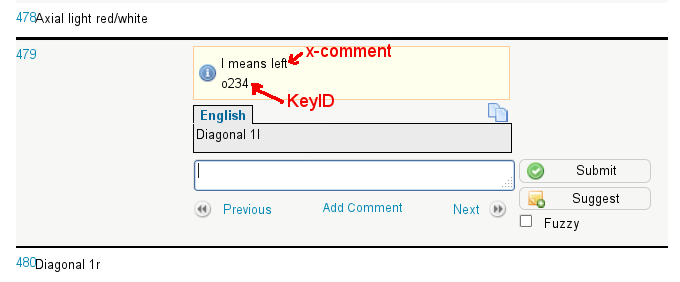
This is how it will look like in Pootle, when we will start to translate LibreOffice 3.6. Next to the KeyID the x-comment will appear, if there is one. Now it is up to translators and developers to write good comments for the problematic parts of the UI. Give context, explain things, when someting is non-trivial. Please send patches, make new translators’ job easier.
Example from svx/source/dialog/sdstring.src:
String RID_SVXSTR_GRDT10
{
Text [ en-US ] = "Diagonal 1l";
Text [ x-comment ] = "l means left";
};
Currently there are no comments in xml configuration files, but if there were, an entry would look like this:
<prop oor:name="VerbUIName">
<value xml:lang="x-comment">This is the Open command.</value>
<value xml:lang="en-US">~Open</value>
</prop>
Hinting in the upcoming 3.5
 LibreOffice 3.5 has got extraordinary typographical capabilities with the improved Graphite port of the new versions of Linux Libertine and Linux Biolinum font families: new and improved font variants from Philipp Poll et al., like the excellent Linux Libertine Display G (true size variant of Linux Libertine for 16pt or more) and the new bold and semibold variants (see also LinuxLibertine.org); font features, like true small caps, old figures, ligatures, proportional numbers have been extended with proper combining diacritics for scientific texts and several languages, and with extended superiors (also true size variant) for typesetting of captions, footnotes, etc., see release notes/examples of the Graphite fonts.
LibreOffice 3.5 has got extraordinary typographical capabilities with the improved Graphite port of the new versions of Linux Libertine and Linux Biolinum font families: new and improved font variants from Philipp Poll et al., like the excellent Linux Libertine Display G (true size variant of Linux Libertine for 16pt or more) and the new bold and semibold variants (see also LinuxLibertine.org); font features, like true small caps, old figures, ligatures, proportional numbers have been extended with proper combining diacritics for scientific texts and several languages, and with extended superiors (also true size variant) for typesetting of captions, footnotes, etc., see release notes/examples of the Graphite fonts.
The main problem of the old versions of the Graphite TrueType fonts was the ugly hinting (the PostScript Type 2 hinting of the original OpenType fonts has been lost by transformation, and replaced by Fontforge autohinting). Fortunately (also thanks to the ttfautohint related article of Libre Graphics World editor Alexandre Prokoudine), I was be able to fix the hinting by the new FreeType tool ttfautohint, so Linux Libertine G and Biolinum G Graphite fonts of LibreOffice 3.5 are suitable for digital publishing, too. Moreover, ttfautohint gives better result in a few places, than the original OpenType hinting, see the bad space in the Linux Libertine Italic text “laz y”, or the bad “w” in the Biolinum Bold and Italic OpenType text. (Click on the picture to see the three different hintings in Adobe Reader on Linux).
Grammar checking in LibreOffice
 Competitive grammar checking would be a nice improvement for LibreOffice. Supported by FSF.hu Foundation, Hungary, I have made two sentence checking patches to the English and Hungarian dictionary extensions of LibreOffice, based on the Lightproof Python UNO environment: see the related issue, the description and the standalone extensions. [Update: source code, Lightproof editor extension]
Competitive grammar checking would be a nice improvement for LibreOffice. Supported by FSF.hu Foundation, Hungary, I have made two sentence checking patches to the English and Hungarian dictionary extensions of LibreOffice, based on the Lightproof Python UNO environment: see the related issue, the description and the standalone extensions. [Update: source code, Lightproof editor extension]
One of the main concepts of “sentence checking” is to break the bad habit of grammar checkers, the annoyingly frequent false alarms. Reporting all potential (but usually not) problems isn’t able to replace proofreading, but very frustrating: “the most useless feature ever added to Microsoft Word […] With this feature, an infinite number of monkeys will analyze your writing and present you with useless grammar complaints while not alerting you to actual grammatical errors because computers don’t understand grammar. Sure, it sounds great on a box—or a promotional Web site—but anyone who knows, knows that grammar checking is a sham. Just say no.” (Jason Snell), “Computer grammar checking really is terrible. […] The things they are good at, like spotting the occasional the the typing error, are very easy there are very few of them. For the most part, accepting the advice of a computer grammar checker on your prose will make it much worse, sometimes hilariously incoherent. If you want an amusing way to whiling away a rainy afternoon, take a piece of literary prose you consider sublimely masterful and run the Microsoft Word™ grammar checker on it, accepting all the suggested changes.” (Geoffrey K. Pullum, cited by Wikipedia), “My take is that we should encourage students to spell check and revise accordingly, but skip the grammar check and proofread instead.” (Mark Pennington). One of the most important improvements of the last few Microsoft Office versions was lowering the “sensitivity” of the grammar checker, responding to customer feedback (source).
In the next few examples I will show how can we make more precise grammar checking:
First rule: we don’t need to catch all mistakes. In fact, we cannot catch all mistakes. We have got only “monkeys”, and often debatable and controversial concepts about grammatical correctness.
Example 1. Capitalization
The following Lightproof rule searches the sentence beginning lower-case letters, and suggests upper-case ones:
^([a-z]) -> =\1.upper() # Missing capitalization?
Unfortunately, there will be many false alarms, especially after abbreviations, because Lightproof has a very simple default sentence boundary detection based on only the paragraph beginning, and sentence ending punctuation (full stop, exclamation mark and question mark). We can check the previous word for abbreviations by a fast Python regex object called abbrev:
^([a-z]) <- not abbrev.search(word(-1)) ->
=\1.upper() # Missing capitalization?
[code]
# pattern matching for common English abbreviations
abbrev = re.compile("(?i)\b([a-z]|acct|approx|\
appt|apr|apt|assoc|asst|aug|ave|avg|co(nt|rp)?|\
ct|dec|defn|dept|dr|eg|equip|esp|est|etc|excl|\
ext|feb|fri|ft|govt?|hrs?|ib(id)?|ie|in(c|t)?|\
jan|jr|jul|lit|ln|mar|max|mi(n|sc)?|mon|Mrs?|\
mun|natl?|neg?|no(rm|s|v)?|nw|obj|oct|org|orig|\
pl|pos|prev|proj|psi|qty|rd|rec|rel|reqd?|resp|\
rev|sat|sci|se(p|pt)?|spec(if)?|sq|sr|st|subj|\
sun|sw|temp|thurs|tot|tues|univ|var|vs)\.")
The sentence segmentation is better, but not enough for a non-intrusive grammar checker (see also the similar decision of Raphael Mudge, author of the more sophisticated and resource-intensive AtD grammar checker here). We will limit the default checking only for paragraph capitalization, more precisely, checking for the first sentence of a paragraph. The difference is important: lower-case list items seem paragraphs for grammar checker clients of LibreOffice, so we check only the paragraphs with more sentences:
^([a-z]) <- re.search("^[a-z].*[.?!] [A-Z]", TEXT)
and not abbrev.search(TEXT) -> = \1.upper()
# Missing capitalization?
(The string variable TEXT contains the full text of the paragraph.)
Second rule: we have to limit false alarms to zero or near zero.
Example 2. Article a/an
The choice of “a” or “an” is determined by phonetic rules and in some cases, also spelling conventions, see Wikipedia. We have to care about the non-standard pronunciation and writing, too, like the form “an HTML” where the letter H pronounced as [ˈheɪtʃ] (see Wikipedia and BBC), and the rare, but similarly allowed spelling conventions: “an hotel”, “an historic” etc. A relevant Lightproof rule to test the “a”:
# pattern "vow" matches words beginning with vowels:
vow [aeiouAEIOU]\w*
a {vow} <- {vow} <> {vow}.upper() and not
({vow} in aA or {vow}.lower() in aA)
and spell({vow}) -> an {vow} # Bad article?
[code]
aA = set(["eucalypti", "eucalyptus", "Eucharist", "Eucharistic",
"euchre", "euchred", "euchring", "Euclid", "euclidean", "Eudora",
"eugene", "Eugenia", "eugenic", "eugenically", "eugenicist",
...])
One of the most interesting elements of the condition is the final spelling dictionary lookup
by the function spell(): this step limits the grammar checking for the known words. Missing words from the exception list (here: “aA”) and from the spelling dictionary won’t result false alarms, for example for the expression “a uremic” or the rare “a usuress”.
Third rule: Don’t hurt people unnecessarily.
Example 3. Spacing
Instead of annoying multiple spaces, like
" +" -> " " # Remove repeating spaces or use tabulators/styles for formatting.
it’s better to check only double (maybe triple) spaces between words. There is living typewriter tradition in the digital age among the users of word processors, too, see sentence spacing with double spaces. So the proposed grammar checker has got three options for spacing: a default option for word spacing, and two optional for sentence spacing and the bad positioning with multiple spaces.
Example 4. Grammar checking based on detailed language data
Recent English module contains only the following example for morphological analysis:
([Tt])his {abc} <- option("grammar") and morph({abc}, "Ns") ->
\1hese {abc}\n\1his, {abc} # Did you mean:
There are several things here to limit false alarms. This is an optional rule (see the option(“grammar”) condition). The morph() function searches unambiguously plural nouns (“Ns”) using Hunspell and language data of Hunspell dictionaries, and the rule checks only lower-case words after “This” or “this”, so the likely bad expression “this mice” will be detected, but not in the “Why is this Mice of Men a challenged book?”. Extending the English dictionary of LibreOffice with part-of-speech and morphological data will help to add more sophisticated grammar checking rules, for example with conversion of the huge rule set of LanguageTool development.
Other concept of sentence checking for LibreOffice is to provide optional tools for proofreading, pre-press formatting and desktop publishing. Not so precise grammar checking is one of these tools, eg. the option “capitalization” of the suggested grammar checker of LibreOffice extends the checking of the capitalization for all sentences, not only for the first ones in the paragraphs.
Feature lists of the recent English module
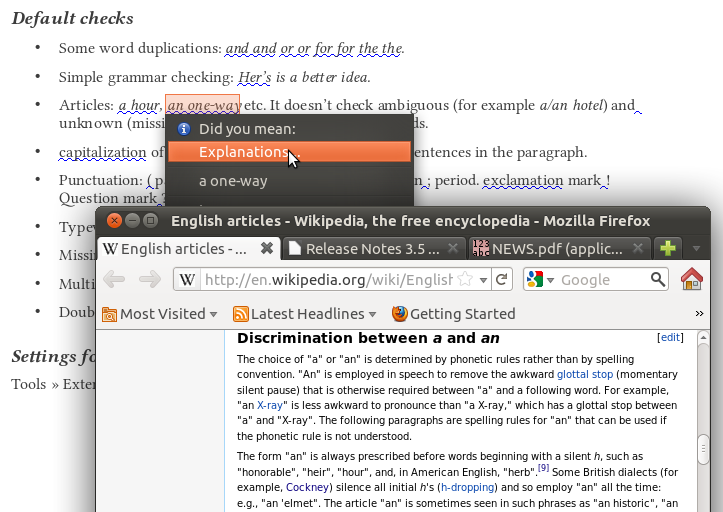
Default checks
- Punctuation (unnecessary spaces before punctuation, missing spaces after punctuation, hyphen instead of n-dash, real double quotation marks and multiplication sign)
- A/an article (with the described improvements)
- Word spacing (not sentence spacing)
- Paragraph capitalization (unwitting paragraph breaks)
- Simple word duplication (and and, or or, for for, the the)
- Longer explanations, using relevant Wikipedia articles (see first screenshot)
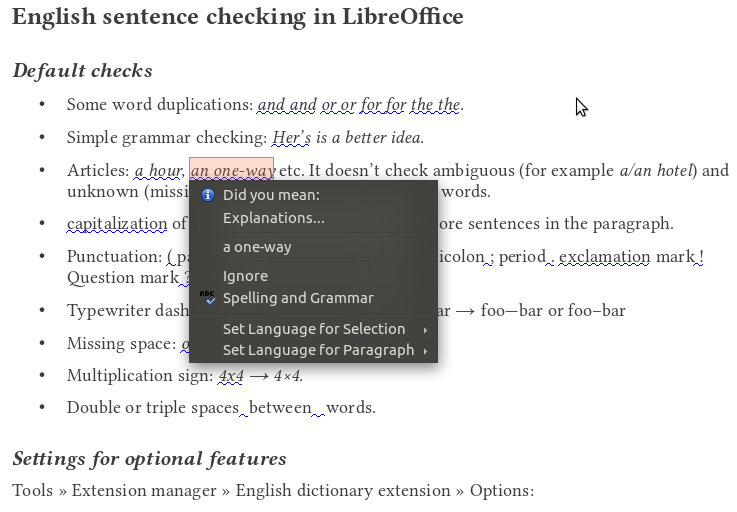
Optional features
- More grammar checks (a few examples using Hunspell morphological analyzer and the English dictionary)
- More punctuation checks (n-dash/m-dash, unpaired quotation marks and parentheses, typographical apostrophe and ellipsis)…
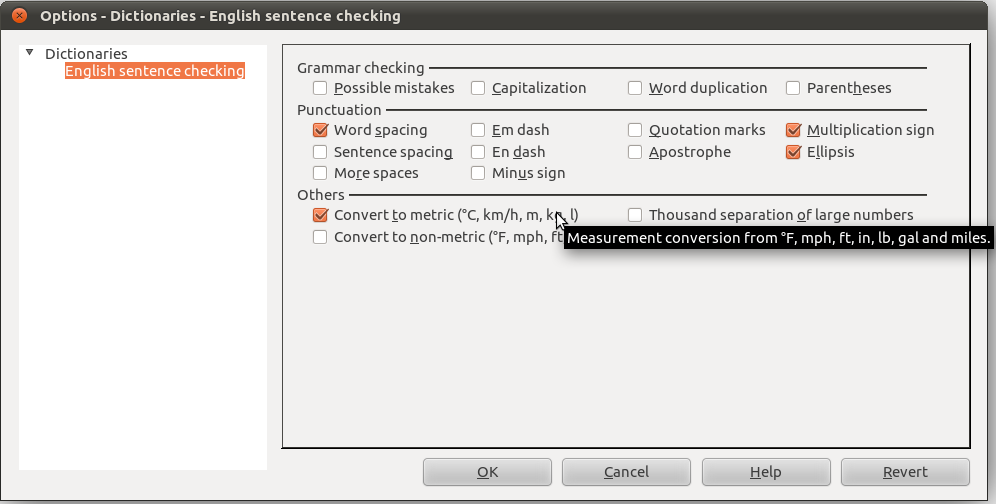
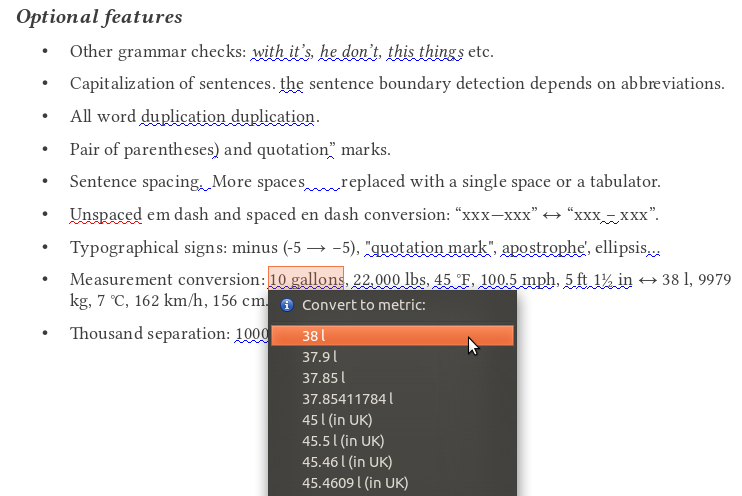
- Measurement conversion (lb/kg, mph/km/h, °F/°C, ft/yd/in/m/cm/mm, mile/km, gal/pint/l)
- Thousand separation (common or ISO)
- Sentence capitalization
- Other word duplication
- Sentence spacing (double spaces)
- Formatting with spaces (more than 3 spaces)
- Settings (a little hidden yet): in Tools » Extension manager… choose “English spelling etc. dictionaries” extension and click on its Options button.
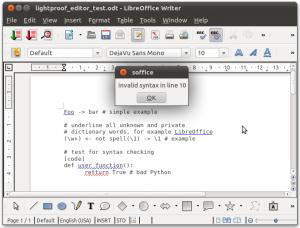
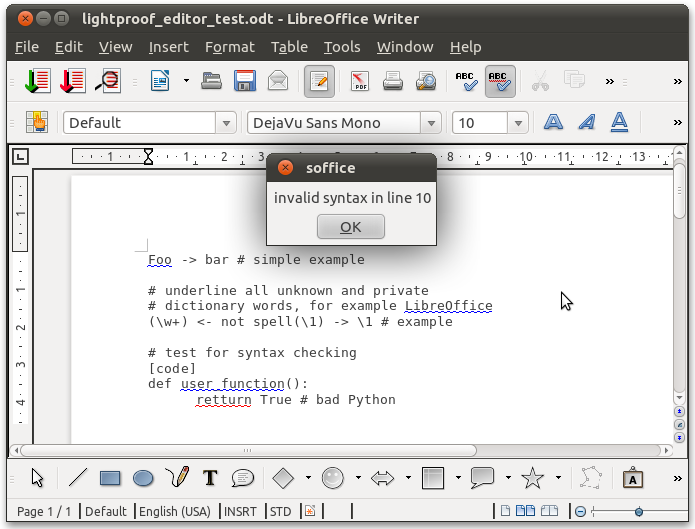
Features of Lightproof rule editor
- LibreOffice extension, downloading, description
- Special grammar checking component + LibreOffice toolbar for rule compiling and debugging
- Run-time compilation and update of its grammar checking component
- Debugging of user code (rule conditions and Python user functions)